|
مراکز داده بر تکنولوژی های نرم افزاری جدیدی تکیه می کنند که نقش اساسی را در گسترش قابلیت های یک سازمان enterprise ایفا می کنند. دیتاسنترهای پیشین، معماری three-tier را به کار می برند که در آن سرورها مبتنی بر مکان شان درون pod هایی تقسیم بندی می شوند ( شکل 1)
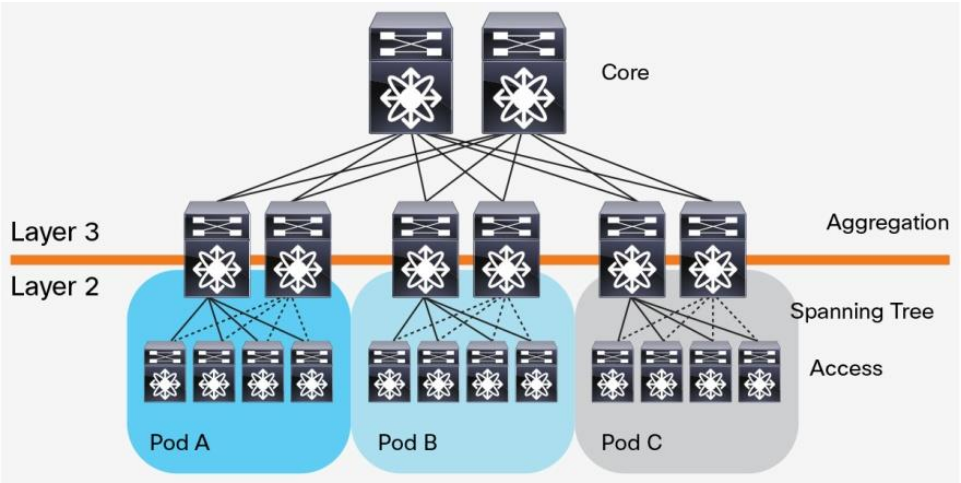
شکل 1 – طرح سه لایه ای مرکز داده
این معماری شامل روترهای core ، روترهای aggregation (یا همان distribution router) و سوییچ های access می شود. بین روترهای aggregation و سوییچ های access ،از پروتکل STP برای جلوگیری از ایجاد loop در لایه 2 شبکه استفاده می شود. پروتکل STP از چندین ویژگی پشتیبانی می کند: سادگی و تکنولوژی plug-and-play که به تنظیمات اندکی نیاز دارد. VLAN ها درون هر pod بسط داده می شوند به طوری که مکان سرورها آزادانه درون pod ها تغییر می کند بدون اینکه نیازی به تغییر آدرس IP و تنظیماتِ default gateway باشد. با این حال STP نمی تواند از مسیرهای ارسالِ موازی استفاده کند و همیشه مسیرهای افزونه در یک VLAN را مسدود می کند.
برای آشنایی بیشتر با معماری و توپولوژی
leaf-spine به ادامه مطلب مراجعه نمایید.
مشاهده پست مشابه :
آنتی ویروس اینترنت سکیوریتی بیتدیفندر | Bitdefender Internet Security
ن : محمد
ت : شنبه 9 آذر 1398
|
|
Nexus NX-OS و Catalyst IOS چه تفاوتی با یکدیگر دارند
در
بخش اول
این مقاله،
خانواده سوئیچ های Nexus سیسکو
را معرفی کردیم. در این مقاله به بررسی سیستم عامل سوئیچ های Nexus سیسکو و مقایسه این سری سوئیچ ها با سوئیچ های Catalyst میپردازیم. در انتهای این مقاله موقعیت های مناسب برای استفاده از هر کدام از سری سوئیچ های Nexus سیسکو را بررسی خواهیم کرد.
سیستم عامل سوئیچ های
Nexus
سیسکو
(NX-OS)
نرمافزار NX-OS سیسکو، سیستم عاملی برای کلاس دیتاسنتر میباشد که از پایه برای ماژولار، انعطاف پذیر و کارآمد بودن ساخته شده است. این سیستم عامل برای اجرا در دیتاسنترهای حساسی مناسب است که تحمل خطا و قابلیت اطمینان در آنها از اهمیت بالایی برخوردارند.
معماری
سیستم عامل NX-OSمیتواند سه عملکرد اصلی دیتاسنتر را با داشتن توانایی پردازش پروتکلهای ذخیره سازی و پروتکلهای لایه دویی و لایه سهای ارائه کند. هر یک از این سرویسها در NX-OS به صورت یک پردازش محافظت شده مستقل اجرا میشود. در واقع هر پردازش non-kernel در فضای محافظت شدهی مموری خود اجرا میشود، که این موضوع قابلیت تحمل خطا را ارائه میکند به طوریکه هر مشکلی در آن پردازش به وجود آید در همان پردازش ایزوله میشود. برای مثال اگر یک سرویس لایه دویی مانند
RSTP
از کار بیوفتد، تاثیری روی سرویسهای دیگر که همزمان در حال اجرا هستند مانند سرویس لایه سهای EIGRP نمیگذارد. باید به این نکته هم اشاره کنیم که NX-OS بر پایه کرنل Linux میباشد، بنابراین از مزیتهای ارائه شده توسط مطمئنترین سیستم عامل بهرهمند میباشد.
برای رسیدن به مصرف بهینه پردازنده و مموری، اکثر امکانات NX-OS به صورت پیش فرض فعال نیستند. پس اگر نیاز باشد که یک تکنولوژی مانند UDLD به کار گرفته شود، این قابلیت باید به صورت دستی فعال شود. نکته ای که در مورد لایسنس NX-OS وجود دارد، NX-OS بازهی 120 روزهای را برای تست در نظر گرفته است. در واقع این بازهی زمانی مشتریان را قادر میسازد تا بتوانند امکانات را قبل از خرید لایسنس، تست کنند.
متخصصانی که با محیط CLI سیستم عامل قدیمیتر IOS آشنایی دارند، برای استفاده از کارکردهای پایه NX-OS با مشکلی مواجه نخواهند شد. از طرفی برای کسانی که تجربهی کار با IOS را دارند، نرم افزار رسمی سیسکو
Cisco IOS to NXOS Configuration Converterمیتواند استفاده از NX-OS را سادهتر کند. این نرمافزار آنلاین رایگان میباشد و از پیکرندی IOS سوئیچهای Catalyst 4900 و
سوئیچ های Catalyst 6500پشتیبانی میکند، که میتوانند به پیکربندی در سیستم عامل NX-OS برای
سوئیچهای Nexus 3000،
سوئیچ های Nexus 5000،
سوئیچ های Nexus 7000و
سوئیچ های Nexus 9000تبدیل شوند.
تفاوتهای اصلی میان
Nexus NX-OS
و
Catalyst IOS
تفاوتهای عمدهای میان سیستم عامل NX-OS و سیستم عامل IOS وجود دارد که قبل از اینکه با NX-OS کار کنید باید با آنها آشنا باشید. این تفاوتها شامل موارد زیر میشود:
- NX-OS از مدل لایسنس دهی feature-based استفاده میکند. امکاناتی مانند UDLD
و FCoE
که به صورت پیش فرض فعال نیستند و آنها را میتوان با دستورات پیکربندی فعال کرد. تا زمانی که قابلیتی را فعال نکنیم، دستورات پیکربندی برای آن قابلیت در دسترس نخواهند بود.
- NX-OS از قابلیت VDC بر روی پلتفرم Nexus 7000 پشتیبانی میکند. این قابلیت یک دستگاه سخت افزاری را قادر میسازد تا به چند دستگاه منطقی تقسیم شود. به صورت پیش فرض سوئیچ از Default VDC استفاده میکند.
- به صورت پیش فرض، Telnet غیر فعال و SSHv2
فعال میباشد.
- کاربر مدیر پیشفرض admin میباشد. دیگر امکان ورود به دستگاه با پسورد به تنهایی وجود ندارد.
- NX-OS از یک kickstart image و یک system image استفاده میکند. کرنل لینوکس توسط kickstart image ارائه میشود و system image عملکردهای لایه 2/3 و امکاناتی مانند OTV، DHCP و … را ارائه میکند.
- NX-OS از قابلیت Checkpoint & Rollback پشتیبانی میکند. این قابلیت شما را قادر میسازد تا اسنپشاتهایی از پیکربندی دستگاه ایجاد کنید و بتوانید تغییرات در هر لحظهای که میخواهید، بدون وقفهای در کارکرد دستگاه، برگردانید.
- تمامی اینترفیسهای Ethernet با نام Ethernet شناخته میشوند. دیگر اثری از نامگذاریهای FastEthernet، GigabitEthernet، TenGigabitEthernet وجود ندارد.
- نامگذاری EtherChannel در IOS به Port-Channel در NX-OS تغییر یافته است.
- دستور Write memory دیگر در دسترس نیست و به جای آن میتوان از دستور copy running-config startup-config استفاده کرد.
- در NX-OS دستورات show در هر دو مود exec و config به یک فرم استفاده میشوند. در IOS برای استفاده از دستور Show در مود config باید قبل از آن از دستور do استفاده کنیم. برای مثال:

- دستور show حتی در مود configuration هم help را ارائه میکند.
- از Slash برای نمایش Subnet mask
آدرسهای IPv6و IPv4 پشتیبانی میشود.

- دو مدل پیکربندی برای پروتکلهای مسیریابی وجود دارد: IGP که مدل interface-centric را دنبال میکند. BGP که مدل neighbor-centric را دنبال میکند.
برای هر موردی، دستور alias موجود در NX-OS میتواند برای ساخت یک نام مستعار و میانبر استفاده شود. برای مثال، برای استفاده از دستور write بر روی NX-OS برای ذخیره سازی پیکربندی در حال اجرا، از دستور زیر میتوان استفاده کرد:

این alias باعث میشود با اجرای دستور write، دستور copy running-config startup config اجرا شود.
مقایسه سوئیچ های رده بالای
Nexus
و
Catalyst
محصولات خانواده سوئیچ های Nexus سیسکو به طور عمده برای محیط های دیتاسنتر طراحی شدهاند و نسبت به سوئیچ های core کاتالیست مزایای زیر را ارائه میکنند:
- Interface: سوئیچهای سری Nexus 7000 از پورتهای 100GbE پشتیبانی میکنند. سوئیچهای core کاتالیست 6500 و 6800 تا پورت هایی با سرعت 40GbE ارائه میکنند.
- Capacity: بیشترین ظرفیت ارائه شده توسط سری Nexus 7000 (سوئیچ Nexus 7700) برابر 42Tbps و سری Nexus 9000 (سوئیچ Nexus 9500) برابر 60Tbps میباشد. در سمت دیگر، بشترین ظرفیت ارائه شده توسط کاتالیست 6800 بسیار کمتر از این مقدارها و برابر 6Tbps میباشد.
- Port Scalability: با توجه به تراکم بالای پورت ها (1G، 10G، 40G) ، خانواده سوئیچهای Nexus نسبت به سوئیچهای Catalyst 6500/6800 از مقیاس پذیری بالاتری برخوردار هستند.
- High Availability: محصولات خانواده Nexus میتوانند از تکنولوژی vPC استفاده کنند، که یکی از رایجترین قابلیت های HA سوئیچ های Nexus و مشابه Catalyst VSS mode میباشد. این قابلیت برای ارائهی multi-chassis link aggregation استفاده میشود. تفاوت اصلی میان این دو این است که vPC برخلاف VSS روی یک control plane اتکا نمیکند، یعنی دو سوئیچ Nexus به صورت مجزا فعالیت های خود را انجام میدهند.
- قابلیت VDC موجود درNexus 7000 توانایی تقسیم کردن این سوئیج به چندین سوئیچ منطقی را ارائه میکند. این سوئیچ های منطقی که مستقل ازهم میباشند، جز اتصال از طریق کابل فیزیکی راهی برای ارتباط با یکدیگر ندارند (پورتی که در یک VDC میباشد به پورتی که در VDC دیگری است از طریق کابل متصل شود). برای سوئیچ هایی که بر پایه SUP1 یا SUP2 میباشند بیشترین تعداد VDC که پشتیبانی میشود برابر 4 و برای سوئیچ هایی که بر پایه SUP2E
میباشند برابر 8 میباشد. قابلیت VDC در واقع برای هر سوئیچ منطقی یک control plane جداگانه به کار میگیرد. تکنولوژی مجازی قابلیت VDC، مزیت یکپارچه سازی چند سوئیچ Nexus را ارائه میکند.
- سوئیچ های سری Nexus 5000 و 7000 و 9000 از Fabric Extenderهای سری Nexus 2000 پشتیبانی میکنند. این ویژگی منحصر به فرد سوئیچ های Nexus میتواند مدیریت، کارکرد و گسترش شبکهی دیتاسنتر را ساده کند.
- سوئیچ های سری Nexus 7000 میتوانند از تکنولوژی های مختلف DC interconnection پشتیبانی کنند در حالیکه سوئیچ های Catalyst 6500/6800 این توانایی را ندارند. در واقع سری Nexus 7000 از تکنولوژی های OTV، VXLAN و Fabric path پشتبانی میکند.
- NX-OS سیستم عامل قدرتمند تری نسبت به IOS میباشد. NX-OS از پایه برای ماژولار، انعطاف پذیر و کارآمد بودن ساخته شده است.
- سوئیچ های سری Nexus 7000 و 5000 با توجه به پشتیبانی آنها از پروتکل های ذخیره سازی اطلاعات (FC و FCoE)، میتوانند شبکهی Converge LAN/SAN را ارائه کنند. سوئیچ های Catalyst 6500/6800 از این پروتکل ها پشتیبانی نمیکنند.
- سوئیچ های Nexus همانند سوئیچ های Catalyst 6500/6800 از service module line card ها مانند FWSM
و WiSM
پشتیبانی نمیکنند.
- سوئیچ های Nexus برخلاف سوئیچ های Catalyst 6500/6800 از قابلیت NAT پشتیبانی نمیکنند.
موارد استفاده سوئیچ هایNexus سیسکو
در این بخش به بررسی موقعیت های مناسب برای استفاده از خانواده سوئیچ های Nexus سیسکو در معماری های مختلف دیتاسنتر میپردازیم.
معماری دیتاسنتر Single Tier
سوئیچ سیسکو سری Nexus 7000 در معماری دیتاسنتر Single tier میتواند در هر دو لایه access و core استفاده شود. در لایه access، ارتباط میان سرورها را میتوان با linecard های 48 پورت Gigabit Ethernet که راهکاری ارزان قیمت میباشد یا linecard های 32 پورت 10Gigabit Ethernet (اگر پورت های 10GE نیاز باشد)، برقرار کرد.
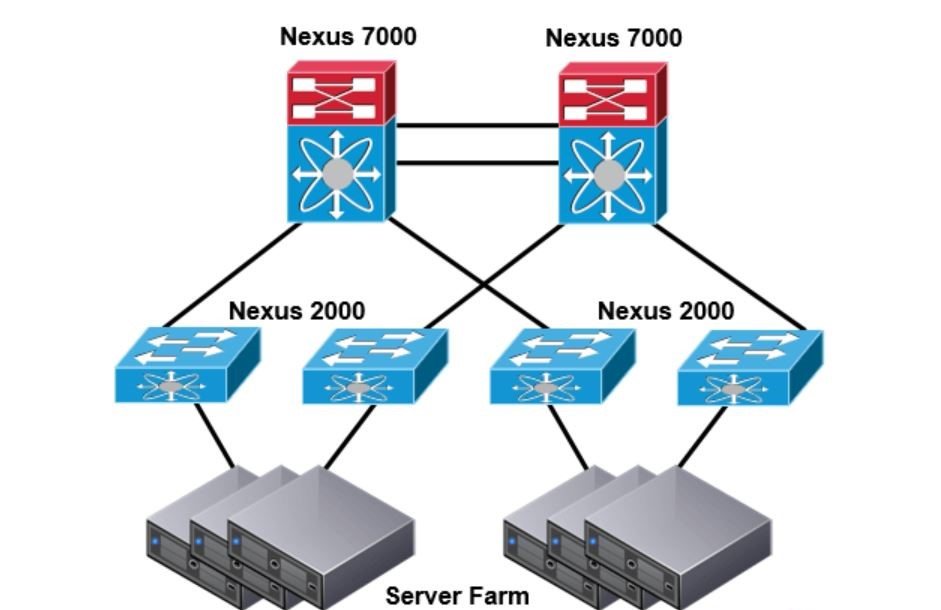
دیتاسنترهایی که معماری single tier دارند میتوانند با اتصال Cisco Nexus 2000 fabric extender ها به سوئیچ های Nexus 7000 گسترش یابند تا ارتباط بین سرورها را برقرار کنند. نکته ای که باید به آن اشاره کرد این است که Nexus 2000 فقط برای برقرای ارتباط میان سرورها و هاست ها باید استفاده شود (برای ارتباط میان سوئیچ ها استفاده نمیشود). این کانفیگ، راهکاری با
طراحی ToR
برای سرور ها ارائه میکند و لایه های access، aggregation و core را در یک لایه خلاصه میکند که سوئیچ Nexus 7000 به عنوان مرکز مدیریتی عمل میکند. اگر محدودیت بودجه وجود داشته باشد، Nexus 9000 بهترین جایگزین Nexus 7000 میباشد. برای دیتاسنتر های کوچک، یک جفت سوئیچ Nexus 5000 در single tier راهکار کم هزینه و مناسبی میباشد.
معماری دیتاسنتر Tow Tier
در این معماری Nexus 2000 fabric Extender ها به سوئیچ های سری Nexus 5000 متصل میشوند. سوئیچ Nexus 5000 به عنوان سوئیچ لایه access با
طراحیEoR
عمل میکند و از طریق لینک های مختلفی به دو سوئیچ Nexus 7000 متصل میشود. این توپولوژی شامل لایهی access و لایهی ترکیبی از دو لایهی aggregation و core میشود.
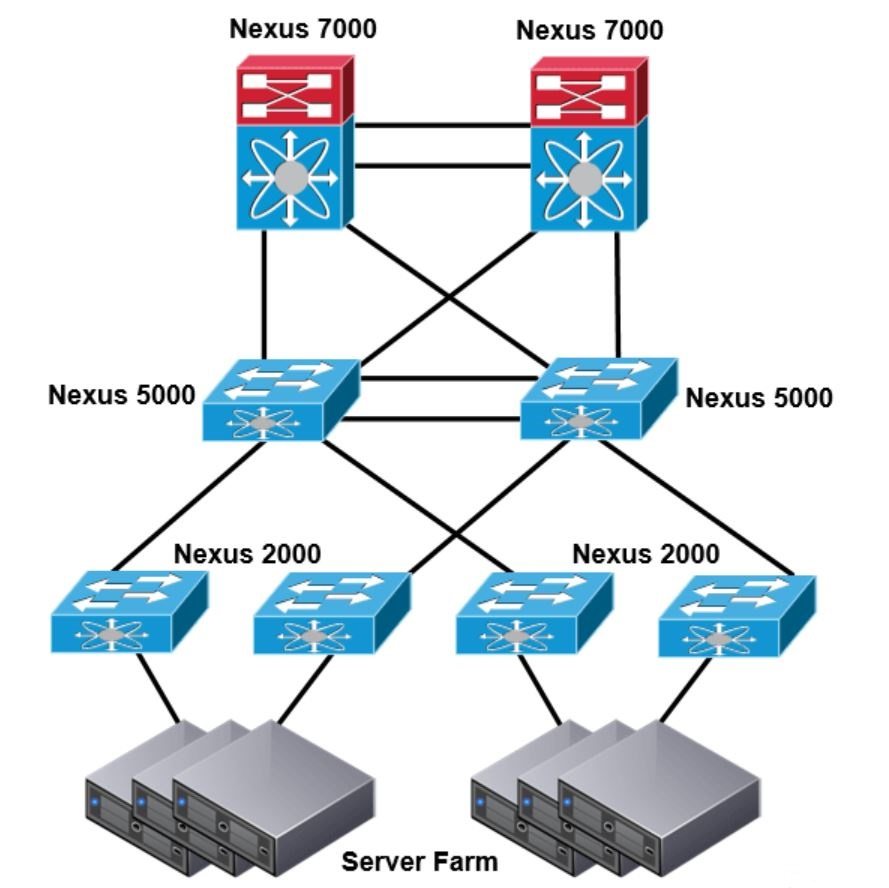
معماری دیتاسنتر Three Tier
با توجه به لایه access و محل قرار گرفتن سوئیچ های Nexus 5000 و Nexus 2000 این معماری مانند معماری دیتاسنتر tow tier میباشد. با این حال تعدادی سوئیچ Nexus 7000 برای لایه aggregation استفاده میشود. لایه core هم از یک جفت سوئیچ Nexus 7000 تشکیل شده است.
:: برچسب ها :
Nexus NX-OS چیست,
Catalyst IOS چیست,
Nexus NX-OS و Catalyst IOS چه تفاوتی با یکدیگر دارند,
تفاوت میان Nexus NX-OS و Catalyst IOS,
ن : محمد
ت : يکشنبه 12 خرداد 1398
|
|
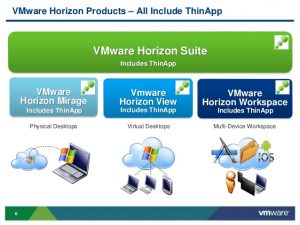
VMware محصولات گوناگونی از Horizon را عرضه کرده است که همه این محصولات برای ارائه خدمات به کاربران در یک مجموعه واحد به نام VMware Horizon Suite قرار می گیرند. ادمین با استفاده از مجموعه Horizon می تواند دسکتاپ ها، اپلیکیشن ها و داده را در سراسر انواع endpoint ها توزیع کند و پاسخگوی تقاضای کاربران برای دسترسی به فایل ها و داده ها در انواع دستگاه ها و در محیط خانه، اداره و … باشد. این مجموعه شامل راهکارهای Horizon View، Horizon Mirage و Horizon Workspace می شود و از قابلیت های زیر پشتیبانی می کند:
- اپلیکیشن ها و دسکتاپ های مجازی
- مدیریت لایه بندی شده ی windows image به همراه مدیریت متمرکز، بازیابی و پشتیبان گیری
- به اشتراک گذاری فایل
- مدیریت فضای کاری متغیر
- Application catalog and management
- مدیریت متمرکز مبتنی بر policy

VMware Horizon View
Horizon View یک راهکارِ
مجازی سازی دسکتاپ
برای تسهیل مدیریت IT، افزایش امنیت و کنترل دسترسی بر کاربرنهایی است که هزینه ها را نیز کاهش می دهد. با استفاده از Horizon View، مدیر شبکه می تواند مدیریت هزاران دسکتاپ را اتوماتیک و ساده سازی کند و از طریق واحد مرکزی با اطمینان دسکتاپ را به عنوان یک سرویس به کاربران تحویل دهد.
مهمترین بخش در Horizon view واسط اتصال یا همان View Manager است که کاربران را به دسکتاپ های مجازی موجودشان در دیتاسنتر متصل می کند. همچنین View شامل پروتکل نمایش از راه دور PCoIP است که جهت ارائه بهترین تجربه کاربری ممکن ، تحت ارتباطات LAN یا WAN استفاده می شود. در نتیجه به کاربر یک دسکتاپ شخصی قدرتمند برای دسترسی به داده، اپلیکیشن ها، ارتباطات یکپارچه (صوت، تصویر و ..) و گرافیک 3D تعلق می گیرد.
علاوه بر موارد ذکر شده، Horizon View شامل ThinApp برای مجازی سازی اپلیکیشن و Composer (برای اینکه به سرعت image های دسکتاپ را از طریق یک golden image ایجاد کند) می شود. کاربران از طریق چندین روش می توانند به دسکتاپ های مجازی خود متصل شوند که شامل View software client بر روی لپتاپ، View iPad یا Android client، مرورگر وب یا یک دستگاه thin-client می شود.
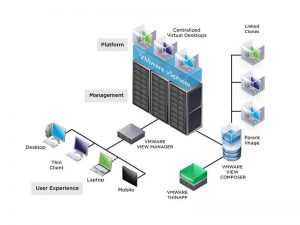
برخی از مولفه های اصلی در Horizon View عبارتند از:
- View Connection Server – یک سرویس نرم افزاری است که از طریق احراز هویت و سپس هدایت درخواست های ورودی کاربر به دسکتاپ مجازی، دسکتاپ فیزیکی یا سرور ترمینال مناسب به عنوان واسطی برای اتصال کلاینت عمل می کند.
- View Agent – سرویسینرم افزاری است که بر روی همه ماشین های مجازی مهمان، سیستم های فیزیکی یا سرورهای ترمینال نصب می شود تا بتوانند توسط View مدیریت شوند.
- View Client – اپلیکیشنی نرم افزاری است که با View Connection Server ارتباط برقرار می کند تا به کاربران اجازه اتصال به دسکتاپ ها را بدهد.
- View Client with Local Mode – نسخه ای از View Client است که جهت پشتیبانی از ویژگی local desktop ارائه شده است و به کاربران اجازه دانلود ماشین های مجازی و استفاده از آنها بر روی سیستم های محلی خود را می دهد.
- View Administrator – یک اپلیکیشن وب است که اجازه کانفیگ View Connection Server ، استقرار و مدیریت دسکتاپ ها، کنترل احراز هویت کاربر، راه اندازی و ارزیابی رویدادهای سیستم و اجرای فعالیت های تحلیلی را می دهد.
- vCenter Server – سروری است که به عنوان administrator مرکزی برای هاست های ESX/ESXi عمل می کند. vCenter Server بخشی مرکزی را برای کانفیگ، اصلاح و مدیریت ماشین های مجازی موجود در دیتاسنتر فراهم می کند.
- View Composer – سرویسی نرم افزاری است که بر روی vCenter server نصب می شود تا View بتواند به سرعت چندین دسکتاپ linked-clone را از یک Base Image واحد در شبکه مستقر نماید.
- View Transfer Server – یک سرویس نرم افزاری است که انتقال داده میان دیتاسنتر و دسکتاپ های View را مدیریت و تسهیل می کند. برای پشتیبانی از دسکتاپ هایی که View Client with Local Mode را اجرا می کنند، View Transfer Server مورد نیاز است.
VMware Horizon Mirage
کمپانی VMware راهکار Mirage را در سال 2012 از شرکت Wanova خریداری نمود و در مجموعه VMware Horizon Suite قرار داد. Mirage راهکاری منحصر به فرد برای مدیریت متمرکز دسکتاپ های فیزیکی یا مجازی، لپ تاپها و یا دستگاه های شخصی مورد استفاده در محیط کار است. هنگامی که Mirage بر روی یک windows PC نصب شده باشد، کپی کاملی را از آن Windows بر روی دیتاسنتر قرار می دهد و آنها را با یکدیگر همگام نگاه میدارد. این همگام سازی شامل تغییراتی از جانب کاربر نهایی در windows می شود که بر روی دیتاسنتر بارگذاری می شوند. همچنین شامل تغییراتی از جانب مدیر شبکه در رابطه با IT است که دانلود شده و به طور مستقیم بر روی windows PC کاربر اعمال می شود. Mirage توانایی مدیریت مرکزی image های دسکتاپ ها را دارد در حالی که مجوز مدیریت محیط local کاربر را به خود کاربرنهایی نیز می دهد.
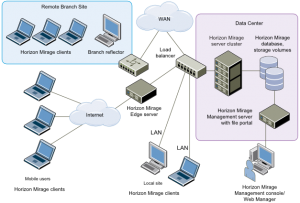
Mirage می تواند PC را به لایه هایی مجزا تقسیم کند که به طور مستقل مدیریت می شوند: لایه Base Image، یک لایه شامل اپلیکیشن هایی نصب شده توسط کاربر و اطلاعات ماشین همچون machine ID و یک لایه شامل داده و فایل های شخصی کاربر.
در این روش، مدیر IT می تواند یک read-only Base Image ایجاد کند که معمولا شامل سیستم عامل (OS) و اپلیکیشن های اصلی همچون Microsoft Office و راهکارهای آنتی ویروسی می شود که به صورت مرکزی مدیریت می شوند. این Base Image می تواند بر روی کپی ذخیره شده از هر PC مستقر شود و سپس با نقطه نهایی هماهنگ شود. به دلیل لایه بندی، Image می تواند patch، بروزرسانی و re-synchronized شود، بدون اینکه اپلیکیشن های نصب شده توسط کاربر یا داده را بازنویسی کند. این ویژگی منجر به بهینه سازی در عملیات شبکه خواهند شد و موارد استفاده زیر را خواهد داشت:
- مدیریت Image واحد – ادمین می تواند یک Image اصلی را مدیریت کند و آن را با هزاران نقطه نهایی
(endpiont) همگام سازد.
- مهاجرت سخت افزاری – با جایگزین کردن Base Image مرتبط با PC یک کاربر نهایی، دسکتاپ کاربر از جمله اپلیکیشن ها، داده و تنظیمات شخصی می تواند به سخت افزار جدید از جمله سخت افزاری از سازنده ای دیگر منتقل شود. این فرآیند را می توان به عنوان بخشی از یک فرآیند مهاجرت سخت افزاری یا برای جایگزینی یک PC دچار خرابی، یا دزدیده شده استفاده نمود.
- اصلاح ریموت اپلیکیشن های آسیب دیده – با اجرای یک Base image ، ادمین می تواند با ریموت زدن به کپی اصلی موجود در دیتاسنتر، مشکلات اپلیکیشن های اصلی یا OS را اصلاح کند.
- مهاجرت محلی از ویندوز Win xP به Win 7 – با جایگزین کردن Base Image مرتبط با PC یک کاربر نهایی، دسکتاپ کاربر از جمله داده و تنظیمات شخصی می تواند تحت شبکه و بدون زیرساخت اضافی از Win XP به Win 7 منتقل شود
برخی از مولفه های موجود در VMware Mirage عبارتند از:
- Mirage Client – فایلی قابل اجرا بر روی client endpoint است و به یک Mirage server یا به load balanced Mirage servers برای واکشی بروزرسانی ها از دسکتاپ مجازی مرکزی، متصل می شود.
- Mirage Management Server – یک کنسول اجرایی است که Mirage Server Cluster را کنترل و مدیریت می کند
- Mirage Server – در دیتاسنتر قرار می گیرد و عملکرد اصلی آن همگام سازی کلاینت ها با دسکتاپ مجازی مرکزی است. همچنین در برابر تحویل لایه Base ، لایه اپلیکیشن و دسکتاپ مجازی مرکزی به کلاینت ها مسئول است و آنها را بر روی کلاینت یکپارچه می کند.
- Mirage Management Console – یک GUI است که برای نگهداری، مدیریت و نظارت بر endpoint های نصب شده استفاده می شود. ادمین می تواند Mirage client ها، لایه های Base و لایه های اپلیکیشن را کانفیگ کند. همچنین با استفاده از Management console می تواند بر روی دسکتاپ مجازی مرکزی تغییرات را اعمال نماید.
- Centralized Virtual Desktop – محتوای کامل هر PC است. این داده به Mirage Server منتقل می شود و در آنجا ذخیره می گردد. از دسکتاپ مجازی مرکزی برای مدیریت، بروزرسانی، patch، پشتیبان گیری، عیب یابی، بازیابی و ارزیابی دسکتاپ در دیتاسنتر استفاده می شود.
VMware Horizon Workspace
یک نرم افزار مدیریت اینترپرایز است که واسط مرکزی واحدی را جهت دسترسی ایمن فراهم می کند. شما در هر زمان و از هر مکانی می توانید از طریق لپتاپ خود، کامپیوترهای خانگی و دستگاه های موبایل android یا ios به اپلیکیشن ها، دسکتاپ ها، فایل ها و سرویسهای وب کمپانی دسترسی یابید
مدیران شبکه از طریق پلتفرم مدیریت مبتنی بر وب می توانند مجموعه ای customize از دسترسی به اپلیکیشن و داده را برای کاربران فراهم کنند که شامل تنظیمات security policy و مجوز استفاده از اپلیکیشن ها می شود. سازمان ها می توانند به سادگی دستگاه های جدید، کاربران جدید یا اپلیکیشن های جدید را برای یک گروه از کاربران بدون نیاز به کانفیگ دوباره دستگاه ها یا endpoint ها اضافه کنند.
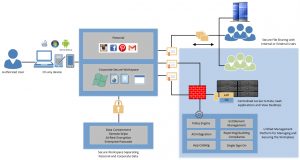
برخی از مولفه های اصلی در Horizon Workspace عبارتند از:
- Workspace Configurator – یک کنسول مدیریتی و واسط کاربری تحت web است که برای مدیریت مرکزی SSL همچنین تنظیمات شبکه، Gateway، vCenter و SMTP در Horizon vApp استفاده می شود.
- Workspace Manager – یک واسط اجرایی تحت وب است که کانفیگ application catalog، user entitlement management و system reporting را ممکن می سازد.
- Workspace Data – به عنوان یک datastore برای فایل های کاربر عمل می کند. سیاست های به اشتراک گذاری فایل ها را کنترل و سرویس های نمایش فایل را فراهم می کند.
- Workspace Connector – قابلیت هایی را برای احراز هویت کاربر local و پیوست Active Directory و سرویس های همگام سازی فراهم می کند. ThinApp catalog loading و View pool synchronization از دیگر خدماتی است که ارائه می دهد.
- Workspace Gateway – به عنوان یک namespace واحد برای همه تعاملات Workspace عمل می کند و دامنه ای برای دسترسی به Worspace ایجاد می کند. همچنین به عنوان بخشی مرکزی برای تجمیع همه اتصالات کلاینت است و ترافیک کلاینت را به مقصد درست مسیریابی می کند.
:: برچسب ها :
Horizon پلتفرمی برای مجازی سازی دسکتاپ,
مجازی سازی دسکتاپ,
ن : محمد
ت : شنبه 13 بهمن 1397
|
|
بکاپ گیری از اطلاعات
یکی از اساسی ترین مسایل برای فهم پشتیبان گیری (backup) و بازیابی (recovery) ، مفهومِ سطوح backup است و اینکه هر یک از این سطوح چه معنایی دارند.
فقدانِ درک صحیح از اینکه این سطوح چه هستند و چگونه به کار گرفته می شوند، منجر شده است که سازمان ها تجربه ناخوشایندی از پهنای باند و فضای ذخیره سازی به هدر رفته ای داشته باشند که جهت از دست نرفتن داده های مهم در
بکاپ گیری از اطلاعات
به آنها تحمیل می شود. همچنین درک این مفاهیم به هنگام انتخاب محصولات یا خدمات حفاظت از اطلاعات بسیار ضروری است.
Full backup
پشتیبان گیریِ کامل، شامل همه داده های کل سیستم می شود. بکاپ کامل از Windows system ، باید کپی هر یک از فایل ها بر روی هر درایو از ماشین یا VM را در برگیرد.
تنها چیزی که در پشتیبان گیری کامل حذف می شود، فایل هایی هستند که از طریق پیکربندی مستثنا می شوند. به طور مثال، اکثر ادمین های سیستم تصمیم می گیرند که دایرکتوری هایی را که در طول بازگردانی ارزشی ندارند (به طور مثال، /boot یا /dev) یا دایرکتوری های شامل فایل های موقتی (به طور مثال، C:\Windows\TEMP در ویندوز، یا /tmp در لینوکس) حذف شوند.
در مورد اینکه فرآیند
بکاپ گیری از اطلاعاتشامل چه فایل هایی باید شود، دو رویکرد وجود دارد: از همه چیز بکاپ بگیرید و چیزهایی را که می دانید به آنها نیاز ندارید را حذف کنید، یا اینکه تنها چیزی را که می خواهید از آن بکاپ بگیرید، انتخاب کنید. اولین رویکرد گزینه ای امن تر است و رویکرد دوم نیز منجر به صرفه جویی در فضای سیستم بکاپ گیری از اطلاعات شما خواهد شد. برخی معتقدند که بکاپ گیری از فایل های اپلیکیشن همچون دایرکتوری های شامل SQL Server یا Oracle ، بیهوده است و به سادگی در طول فرآیند بازگردانی، اپلیکیشن را دوباره بارگذاری می کنند. مشکل رویکرد اخیر این است که احتمال دارد شخصی داده ای ارزشمند را در یک دایرکتوری قرار دهد که برای پشتیبان گیری انتخاب نشده است. به فرض اگر شما تنها دایرکتوریِ home/ یا D:\Data را برای پشتیبان گیری برگزینید، چگونه سیستمِ بکاپ تشخیص خواهد داد که شخصی اطلاعاتی مهم را در دیگر دایرکتورها ذخیره کرده است؟ به همین دلیل، با وجود اینکه رویکرد اول فضای زیادتری را اشغال می کند، پشتیبان گیری از همه چیز روشی امن تر می باشد و تنها فایلهایی که نیازی ندارید، حذف می شوند. البته اگر شما یک محیطِ به شدت کنترل شده داشته باشید که در آن همه داده ها در مکانی مشخص بارگذاری شده باشند و راهکار هماهنگ شده ی مناسبی برای جابجایی سیستم عامل و اپلیکیشن ها در فرآیند بازگردانی داشته باشید، استفاده از راهکار دوم برایتان موثر خواهد بود.
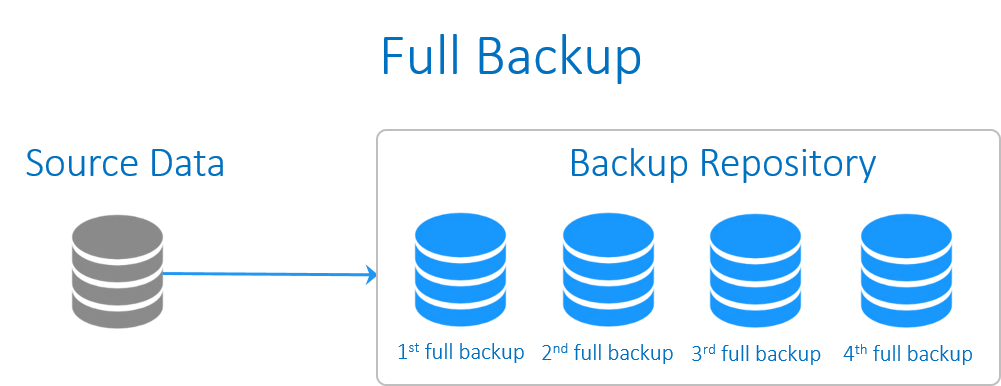
از آنجایی که حجم عظیمی از داده ها باید کپی شوند، در این فرآیند زمان بسیاری صرف خواهد شد (در مقایسه با انواع دیگر از روش های
بکاپ گیری از اطلاعات، این روش 10 برابر زمان بیشتری را صرف می کند). در نتیجه در هر نوبتِ پشتیبان گیری، بارکاری قابل ملاحظه ای به شبکه تحمیل می شود و با عملیات روتینِ شبکه شما تداخل پیدا می کند. همچنین بکاپ گیری از اطلاعات به طور کامل حجم بالایی از فضای ذخیره سازی را نیز اشغال می کند.
به همین دلیل است که
بکاپ گیری از اطلاعاتبه طور کامل تنها به صورت دوره ای گرفته خواهد شد و آن را با انواع دیگر بکاپ ترکیب می کنند.
- ریکاوری سریعِ داده ها به هنگام رخدادِ یک disaster
- مدیریت بهتر ذخیره سازی، از آنجایی که تمام مجموعه داده ها در یک فایل بکاپِ واحد ذخیره می شوند
با وجود اینکه
بکاپ گیری از اطلاعاتبه طور کامل، مزیت های بالا را برای شما به ارمغان می آورد اما شامل نقاط ضعف بسیاری نیز هست:
- اجرای بکاپِ کامل، زمان بسیاری زیادی را به خود اختصاص می دهد
- شما نیاز به یک ذخیره ساز با ظرفیت بسیار بالا خواهید داشت تا بتواند همه بکاپ های شما را دربر گیرد
- از آنجایی که هر فایلِ full backup شامل کل مجموعه داده های شماست (که اغلب محرمانه هستند)، اگر این داده ها به دسترسی شخصی فاقدِ صلاحیت برسند، کسب و کار شما دچار مخاطره می شود. هر چند اگر راهکار بکاپِ شما از ویژگی data protection پشتیبانی نماید، می توان از این خطرات پیشگیری نمود.
incremental backup (بکاپ افزایشی)
بکاپِ افزایشی معمولا از داده هایی پشتیبان می گیرد که از زمان آخرین بکاپِ گرفته شده (هر نوعی از بکاپ که باشد)، تغییری روی آنها صورت گرفته باشد. گرفتن یک بکاپِ کاملِ اولیه از پیش شرط های ایجادِ بکاپِ افزایشی است. و بسته به سیاست های ذخیره سازیِ بکاپ، پس از یک دوره زمانی معین به یک full backup جدید برای تکرار این سیکل نیاز است.
برخی از این نوع بکاپ ها، بکاپ های file-based هستند به این معنا که از همه فایلهایی که نسبت به آخرین زمان بکاپ تغییر کرده باشند، بکاپ تهیه می شود. در حالی که ما به روش های مختلف می کوشیم تا تاثیر I/O ناشی از بکاپها بر روی سرور (به خصوص به هنگام پشتیبان گیری از VM ها) را کاهش دهیم، در این شیوه
بکاپ گیری از اطلاعاتبا چالشی در این مورد مواجه خواهیم شد. چرا که پشتیبان گیری از یک فایل 10GB که تنها 1 MB از آن تغییر کرده است، چندان کارآمد نیست.
به دلیل ناکارآمدی در شیوه file-based، اکثر کمپانی ها به سمت بکاپ افزایشیِ block-based رفته اند که در آن تنها از بلاک های تغییر یافته، بکاپ گرفته می شود. رایجترین روش برای انجام آن هنگامی است که از محصولات نرم افزاری بکاپ تهیه می شود، به طور مثال از VMware یا
Hyper-V
با استفاده از API هر یک از آنها، می توان پشتیبان تهیه نمود. هر App یک API مناسب خود را اعلام می کند که بکاپ افزایشیِ block-based را انجام می دهد.
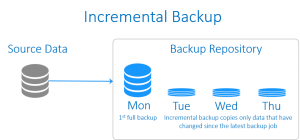
بکاپ افزایشی از سرعت بالایی برخوردار است و در مقایسه با full backup، به فضای ذخیره سازیِ بسیار کمتری نیاز دارد. اما از آنجایی که در این شیوه به بازگردانیِ آخرین بکاپِ کامل و علاوه بر آن کل زنجیره بکاپ های افزایشی نیاز است، فرآیند ریکاوریِ آن مدت زمان بیشتری به طول می انجامد. اگر یکی از بکاپ های افزایشی در این زنجیره بکاپ از دست برود یا صدمه ببیند، ریکاوری کامل آن غیر ممکن خواهد شد.
فواید بکاپ افزایشی:
- از آنجایی که تنها از داده های افزوده شده بکاپ تهیه می شود، فرآیند
بکاپ گیری از اطلاعاتسرعت بسیار بالایی دارد
- به فضای ذخیره سازی کمتری نیاز است
- هر کدام از این بکاپ های افزایشی یک نقطه بازیابی مجزا هستند
معایب بکاپ افزایشی:
- هنگامی که شما نیاز داشته باشید، هم بکاپ کامل و هم همه ی بکاپ های افزایشی متوالی را بازگردانید، سرعت بازگردانیِ کامل داده ها پایین است
- بازگردانیِ موفق داده ها به عدم نقص در تمامیِ بکاپ های افزایشی موجود در زنجیره وابسته است
Differential backup (بکاپ تفاضلی)
Differential backup راهکاری بینابینِ بکاپ افزایشی و بکاپ کامل است. همچون بکاپ افزایشی، در اینجا نیز نقطه آغاز
بکاپ گیری از اطلاعاتوجود یک بکاپ کامل اولیه است. سپس از همه داده ها که از زمان آخرین بکاپ کامل (full backup) تغییر کرده باشند، بکاپ گرفته می شود. در مقایسه با بکاپ های افزایشی، differential backup اکثر داده هایی که در بکاپ های اخیر تغییر کرده اند را ذخیره نمی کند، تنها داده هایی ذخیره می شوند که نسبت به بکاپ کامل اولیه تغییر کرده اند. بنابراین بکاپ کامل، نقطه مبنا برای بکاپ گیری متوالی است. در نتیجه بکاپ differential در مقایسه با بکاپ افزایشی، سرعت بازگردانی داده را افزایش می دهد چرا که تنها به دو قطعه بکاپ اولیه و آخرین بکاپِ differential نیاز است. این نوع از بکاپ گیری از اطلاعات در زمان استفاده از درایوهای tape رواج بسیاری داشت، چرا که تعداد tape های مورد نیاز برای بازگردانی را کاهش می داد. بازگردانی (restore) نیاز به آخرین بکاپ کامل در کنار آخرین differential backup و incremental backup دارد.
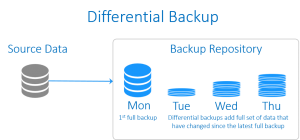
ویژگی ها
از لحاظِ سرعتِ پشتیبان گیری/بازگردانی، بکاپ differential به عنوانِ راهکاری است که در میانِ دو راهکار بکاپِ کامل و بکاپ افزایشی قرار می گیرد:
- عملیات
بکاپ گیری از اطلاعاتدر آن کندتر از بکاپ افزایشی اما سریعتر از بکاپ کامل است
- عملیات بازگردانیِ آن، آهسته تر از بکاپ کامل اما سریع تر از بکاپ افزایشی است
فضای ذخیره سازی لازم برای بکاپِ differential، حداقل در یک دوره مشخص، کمتر از فضای لازم برای بکاپِ کامل و بیشتر از فضای مورد نیاز برای بکاپ افزایشی است.
Mirror backup
این راهکار مشابه با
بکاپ گیری از اطلاعاتبه طور کامل است. این نوع بکاپ گیری از اطلاعات، کپی دقیقی از مجموعه داده ها ایجاد می کند با این تفاوت که بدون ردیابیِ نسخه های مختلفِ فایل ها، تنها آخرین نسخه از داده در بکاپ ذخیره می شود.
بکاپِ Mirror ، فرآیند ایجاد کپی مستقیمی از فایل ها و فولدرهای انتخاب شده، در زمانی معین است. از آنجایی که فایل ها و فولدرها بدون هیچ گونه فشرده سازی در مقصد کپی می شود، سریع ترین
انواع روش های بکاپ گیری از اطلاعات
است. با وجود سرعت افزایش یافته در آن، نقاط ضعفی را نیز به همراه خواهد داشت: به فضای ذخیره سازی وسیعتری نیاز دارد و نمی تواند از طریق رمز عبور محافظت شود.
در این نوع از بکاپ گیری، هنگامی که فایل های بی کاربرد حذف می شوند، از روی بکاپِ mirror نیز حذف خواهند شد. بسیاری از خدماتِ بکاپ ، بکاپِ mirror را با حداقل 30 روز فرصت برای حذف پیشنهاد می کنند. به این معناست که به هنگام حذف یک فایل از منبع، آن فایل حداقل 30 روز بر روی storage server نگهداری می شود.
ویژگی ها
امتیازی که بکاپِ mirror در اختیار شما می گذارد، بکاپی درست است که شامل فایل های منسوخ شده و قدیمی نمی شود.
و اما معایب آن زمانی خود را نشان خواهد داد که فایل ها به صورت تصادفی یا به واسطه ویروس ها از منبع حذف شده باشند.
Reverse Incremental Backup (بکاپ افزایشی معکوس)
در این نوع
بکاپ گیری از اطلاعاتنیز برای شروع به یک بکاپ کامل اولیه نیاز است. پس از ایجاد بکاپِ کامل اولیه، هر بکاپ افزایشیِ موفق تغییرات را به نسخه پیشین اعمال می کند که در نتیجه آن در هر زمان یک بکاپ کاملِ جدید (به صورت مصنوعی) ایجاد می شود. در حالی که کماکان توانایی بازگشت به نسخه های پیشین وجود دارد. هر یک از بکاپ های افزایشیِ اعمال شده به بکاپ کامل، نیز ذخیره می شوند که در زنجیره ای از بکاپ ها، به طور مستمر در پشت سرِ بکاپ کاملِ به روز شده، در جریان هستند.
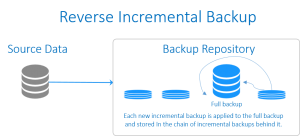
امتیاز اصلی در این نوع از بکاپ گیری فرآیند بازیابی کارآمدترِ آن است، چرا که بخش زیادی از جدیدترین نسخه های داده به بکاپ کامل اولیه اضافه می شود و نیازی ندارید بکاپ های افزایشی را در طول بازیابی بکار ببندید. در گیف زیر فرآیند اجرای این نوع بکاپ نشان داده شده است.

Smart backup (بکاپ هوشمند)
بکاپ هوشمند، ترکیبی از بکاپ های کامل، افزایشی و تفاضلی است. بسته به هدفی که در
بکاپ گیری از اطلاعاتدر نظر دارید و همچنین فضای ذخیره سازیِ در دسترس، بکاپ هوشمند می تواند راهکاری کارآمد را ارائه دهد. جدول زیر ایده ای در رابطه با چگونگی کارکرد این نوع بکاپ، در اختیار شما می گذارد.
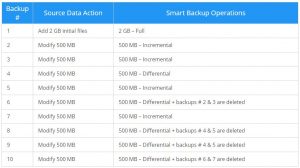
با استفاده از بکاپ هوشمند، همیشه می توانید تضمین نمایید که فضای ذخیره سازیِ کافی برای بکاپ های خود در اختیار دارید.
Continuous Data Protection (محافظت مستمر از داده)
بر خلاف بکاپ های دیگر که به صورت دوره ای انجام می شوند، CDP از هر تغییری در مجموعه داده های منبع log تهیه می کند که از سویی مشابه با بکاپِ mirror است. اختلاف CDP با mirror در این است که log مربوط به تغییرات برای بازیابیِ نسخه های قدیمی تر از داده می تواند بازیابی شود.
Synthetic Full Backup (بکاپ کامل ساختگی)
این نوع از بکاپ شباهت های بسیاری با بکاپ افزایشی معکوس دارد. اختلافِ آنها در چگونگی مدیریت داده هاست. بکاپ کامل مصنوعی با اجرای بکاپ کاملِ مرسوم آغاز می شود که در ادامه مجموعه ای از بکاپ ها افزایشی را در پی دارد. در زمانی معین، بکاپ های افزایشی هماهنگ می شوند و به بکاپ کاملِ موجود اعمال می شوند تا بکاپ کاملی را به طور مصنوعی و به عنوان یک نقطه شروعِ جدید ایجاد نمایند.
بکاپ کاملِ ساختگی، تمامی امتیازات یک بکاپ کامل را دارد، در حالی که زمان و فضای ذخیره سازیِ کمتری را صرف می کند.
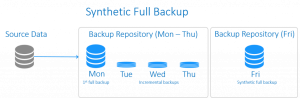
از جمله مزایای بهره وری از بکاپ کامل ساختگی عبارتند از:
- عملیات بازیابی و بکاپ گیریِ سریع
- مدیریتِ بهترِ ذخیره ساز
- نیاز کمتر به فضای ذخیره سازی
- یارهای کاریِ کمتر در شبکه
Forever-Incremental Backup
این راهکار با بکاپ افزایشی عادی متفاوت است. همچون اکثر راهکارهای پیشین برای شروع به یک بکاپ کامل اولیه به عنوان یک نقطه مرجع برای ردگیری تغییرات نیاز دارد. از آن لحظه، تنها بکاپ های افزایشی بدون هیچ گونه بکاپ کاملِ دوره ای ایجاد می شوند.
فرض کنید که شما بکاپ کامل را در روز شنبه ایجاد کردید. با شروع روز بعد، بکاپ های افزایشی به صورت روزانه ایجاد می شوند. در روز یکشنبه دو بلوک جدیدِ A و B در مجموعه داده های منبع ایجاد شده اند. در روز دوشنبه بلوک A حذف و بلوکِ جدید C بر روی منبع ایجاد شده است. در روز سه شنبه بلوک B حذف و بلوک جدید D ایجاد شده است. سیستمِ forever-incremental backup تمامیِ تغییرات روزانه را پیگیری می کند. حذف بلوک های داده تکراری تا فضای ذخیره سازی مورد نیاز برای بکاپ را کاهش دهد.
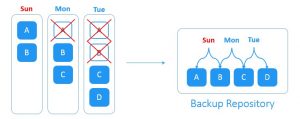
یا توجه به سیاست های ویژه در زمینه نگهداری بکاپ ها، پس از ایجادِ مجموعه ای از بکاپ های افزایشی، نقاط بکاپ گیری و بازیابیِ منقضی شده حذف می شوند تا فضای ذخیره سازیِ اشغال شده در backup repository آزاد شود.
امتیازاتی که روش بکاپ گیریِ forever-incremental نصیب شما خواهد کرد نیز مشابه با روشِ بکاپ کامل ساختگی است.
جمع بندی
در حقیقت راهکار
بکاپ گیری از اطلاعاتخوب یا بد وجود ندارد. باید در نظر بگیرید که چه نوعی از بکاپ گیری برای شما بهترین است و نیازهای ویژه ی سازمانِ شما را بر مبنای سیاست های محافظت از داده، ذخیره سازِ موجود، منابع، پهنای باند شبکه، نواحی داده ای مهم و …. برآورده می سازد.
توجه: برای وضوح تصاویر بر روی آن ها کلیک کنید.
منبع :
Faradsys.com
مشاهده پست مشابه :
KLS Backup 2015 Professional 8.3.2.4 بکاپ گیری از اطلاعات
:: برچسب ها :
بکاپ گیری از اطلاعات,
روش های بکاپ گیری,
انواع روش های بکاپ گیری,
ن : محمد
ت : دوشنبه 1 بهمن 1397
|
|
Hyper-V features a Type 1 hypervisor-based architecture. The hypervisor virtualizes processors and memory and provides mechanisms for the virtualization stack in the root partition to manage child partitions (
virtual machines) and expose services such as I/O devices to the virtual machines.
The root partition owns and has direct access to the physical I/O devices. The virtualization stack in the root partition provides a memory manager for virtual machines, management APIs, and virtualized I/O devices. It also implements emulated devices such as the integrated device electronics (IDE) disk controller and PS/2 input device port, and it supports Hyper-V-specific synthetic devices for increased performance and reduced overhead.
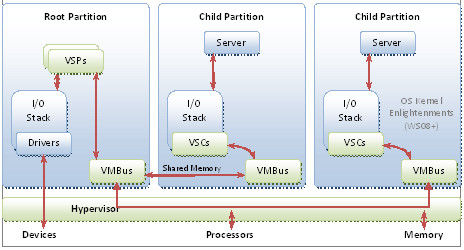
The Hyper-V-specific I/O architecture consists of virtualization service providers (VSPs) in the root partition and virtualization service clients (VSCs) in the child partition. Each service is exposed as a device over VMBus, which acts as an I/O bus and enables high-performance communication between virtual machines that use mechanisms such as shared memory. The guest operating system’s Plug and Play manager enumerates these devices, including VMBus, and loads the appropriate device drivers (virtual service clients). Services other than I/O are also exposed through this architecture.
Starting with Windows Server 2008, the operating system features enlightenments to optimize its behavior when it is running in virtual machines. The benefits include reducing the cost of memory virtualization, improving multicore scalability, and decreasing the background CPU usage of the guest operating system.
The following sections suggest best practices that yield increased performance on servers running Hyper-V role.
source:
microsoft.com
:: برچسب ها :
Hyper-V Architecture,
ن : محمد
ت : دوشنبه 1 بهمن 1397
|
|
بلاک چین
یک سیستم برای نگهداری دفتر حساب های توزیع شده است به طوری که اجازه می دهد سازمانهایی که اعتماد کافی به یکدیگر ندارند بر روی بروزرسانی این دفتر حساب ها به توافق برسند. به جای استفاده از شخص ثالث مرکزی یا فرآیند تطبیق حساب آفلاین،
بلاک چیناز پروتکل های peer to peer استفاده می کند. بلاک چین به عنوان یک دفتر حساب توزیع شده، یک رکورد پاک نشدنی و آنی را فراهم می کند که در میان شرکت کنندگان آن کپی می شود.
بلاک چین
این پتانسیل را دارد که اساسا چگونگی انجام معاملات تجاری جهانی را تغییر دهد. در حال حاضر برخی از معاملات از طریق شخص ثالث انجام و تعیین مسیر می شوند تا صداقت و حفاظت در معامله را تضمین کنند. وجود این اشخاص ثالث می تواند منجر به بروز تاخیرها در پرداخت و حتی افزایش هزینه ها شود. تکنولوژی
بلاک چینمنجر می شود که شرکت کنندگان در شبکه مورد اعتماد تجاری به طور مستقیم معاملاتشان را انجام دهند در حالی که از اعتبار و ثبات معاملاتشان مطمئن خواهند بود. هنگامی که معاملات پیشنهاد شده اعتبار می یابند و توافق بر روی پیامدهای آن به دست می آید، شرکت کنندگان در تکنولوژی بلاک چین، آنها را در بلاکهایی مرتبط به هم و رمزنگاری شده ثبت می کنند که قابل لغو شدن نیستند.
این تکنولوژی به حل و فصل بسیاری از چالش ها در مقیاس enterprise کمک می کند، همچون:
- ایجاد اعتماد در معاملات BTB
نظیر به نظیر، به طوری که از هزینه ها و خطرات واسطه ها جلوگیری می شود
- کاهش روش های دستی، مبادله اطلاعات در معرض خطا و فرآیندها
- پرهیز از هزینه و تاخیرهای تطبیق آفلاین
- کاهش تطبیق های cross-ERP که منجر به خطرات واریز اسناد و ثبت های ضعیف می شود
- کاهش خطرات بالای تقلب در معاملات میان شرکت ها
- بهبود قابلیت رویت اطلاعات به طور آنی در اکوسیستم تجاری
مکانیزم
بلاک چین:
- سیستم
بلاک چینشبکه ای نظیر به نظیر از نودهای معتبر است. هر نود دفتر حسابی حاوی اطلاعات و تاریخچه ای از بروزرسانی ها را نگاه می دارد.
- تغییرات درون این دفترحساب ها، از طریق معاملات پیشنهاد شده توسط طرف های خارجی به وسیله کلاینتها راه اندازی می شود. هنگامی که از طریق معاملات تغییرات رخ می دهد، شرکت کنندگان در
بلاک چینمنطق بیزینس (به اصطلاح قراردادهای هوشمندانه) را اجرا می کند و برای تایید نتایج از پروتکل های اجماع
پیروی می کنند.
- هنگامی که تحت قوانین شبکه توافق به دست می آید، معاملات و نتایج آنها درون بلاک های داده ای دسته بندی می شوند که به واسطه رمزنگاری ایمن و غیرقابل تغییر هستند و توسط هر کدام از شرکت کنندگان به دفتر حساب اضافه شده اند.
- علاوه بر تمام معاملات و نتایج آنها، هر بلاک حاوی هش رمزنگاری از بلاک قبلی است که تضمین می کند، هر گونه سوء استفاده از یک بلاک خاص به راحتی شناسایی شود.
فواید
بلاک چین:
بلاک چینفرآیند زمانگیر و پیچیده در معاملات BTB را با روشی که شفاف، قابل بازبینی و تضمین کننده است، جایگزین می کند. فواید آن برای کسب و کارهای امروزی شامل:
اجتناب از واسطه های متمرکز با استفاده از شبکه کسب و کار نظیر به نظیر
- فرآیندهای سریع تر و اتوماتیک تر
فرآیندها و مبادله داده ها را اتوماتیک می کند. مغایرت های آفلاین را حذف می کند. به طور خودکار اقدامات، حوادث و حتی پرداخت ها بر اساس شرایط از پیش تعیین شده فعال می شوند. فرایندهایی که روزها (یا هفته ها) انجام می شد در حال حاضر به طور آنی انجام می شود.
هزینه ها به واسطه شتاب بخشیدن به معاملات و حذف فرآیندهای واریز اسناد با استفاده از ساختار اشتراکی قابل اعتمادی از اطلاعات مشترک به جای اتکا بر واسطه های متمرکز یا فرآیندهای تطبیق پیچیده کاهش می یابد.
به طور خودکار اقدامات، حوادث، و حتی پرداخت بر اساس شرایط از پیش تعیین شده راه اندازی می شوند. از طریق خودکارسازی فرآیندها برای کار خارج از ساعت های کاری، معاملات را سرعت می بخشد.
شرکت کنندگان بی درنگ معاملات توزیع شده در سراسر شبکه کاری مصوب خود را می توانند مشاهده نمایند. یک سیستم اشتراکی از رکوردها نگهداری می شود که همه در آن به میزان یکسانی از وقایع مطلع هستند.
تقلب را کاهش می دهد در عین حال که با تضمین رکوردهای حیاتی تجاری، پذیرش قوانین تنظیم شده را افزایش می دهد.با استفاده از بلاک های مرتبط رمزنگاری شده داده ها را ایمن نگاه می دارد به طوری که رکوردها نمی توانند بدون شناسایی حذف شوند یا تغییر کنند.
بلاک چیندر مقایسه با پایگاه داده مرکزی
بلاک چینیک دفتر حساب توزیع شده است که به طور مستقیم از طریق گروهی از اشخاص که الزاما مورد اعتماد یکدیگر نیستند، به اشتراک گذاشته می شود بدون اینکه به یک ادمین مرکزی شبکه نیازی باشد. در مقابل یک پایگاه داده سنتی (SQL یا NoSQL) به وسیله نهاد واحدی کنترل می شود. این تفاوت مهمی است به این معنا که:
- هر نود در
بلاک چینبه طور مستقل هر معامله را پردازش و بررسی می کند. یک نود از آنجایی این توانایی را دارد که دارای قابلیت رویت کامل به وضعیت فعلی پایگاه داده، تغییرات درخواست شده توسط یک معامله و امضای دیجیتالی است که سرچشمه معامله را ثبت می کند.
- معاملات و داده های مبتنی بر
بلاک چین، تحمل پذیری بسیار بالایی را به علت افزونگی نهفته در آن دارند.
- بروزرسانی ها توسط شرکت کنندگان پیش از انجام آنها توافق شده است، در مقایسه با یک محیط پایگاه داده معمولی که در آن به روز رسانی ها توسط هر طرف انجام می شود و سپس از طریق پردازش های طاقت فرسا (و اغلب آفلاین) تطبیق داده می شوند.
- نقش آفرینی
بلاک چینتقریبا بی وقفه در حال انجام است چرا که هیچ تاخیری از دفتر مرکزی نقل و انتقال بانکی یا فرآیند های تطبیق وجود ندارد درحالی که پیش از این بررسی ها اغلب در طول شب یا در طول چندین روز یا هفته صورت می گرفت.
:: برچسب ها :
بلاک چین چیست,
بلاک چین,
ن : محمد
ت : چهارشنبه 3 مرداد 1397
|
|
حفاظت از سرور vCenter با VCHAدر مقالات قبل درباره ویژگی HA برای شما صحبت کردیم . اما VCHA قابلیتی است که وظیفه دیگری را برعهده دارد. این موضوع احتمالا یکی از مواردی است که بیشتر وقت خود را در هنگام صحبت با مشتریان صرف آن می کنید. قابلیت (vCenter High Availability (VCHA در نسخه vSphere 6.5 در نوامبر 2016 معرفی شد. قبل از اینکه شروع کنیم چند نکته را باید در نظر داشته باشید . قابلیت VCHA از 3 نود تشکیل شده است. (Active – Passive – Witness) برای راه اندازی تنها به یک vCenter Server Instance License نیاز است. از Tiny Deployment استفاده نکنید. (این مورد برای موارد آزمایشگاهی استفاده میکنند) از هر دو حالت Embedded PSC و Extended PSC پشتیبانی میکند. قابلیت VCHA با DR یکی نیست. بسیار خب ، اولین اقدامی که باید صورت بگیرید ، گرفتن Clone ها میباشد . از نود Active به نود Passive و سپس Witness عملیات Clone گرفتن را طی میکینم. کاری که قبل از گرفتن Clone انجام میدهیم اضافه کردن یک Second Adapter میباشد . و همچنین Primary Adapter را داریم که Management Interface نامیده میشود و شامل FQDN , IP , MAC Address میباشد. این Adapter ها همچنین در نود پسیو وجود دارد اما به صورت آفلاین ، تا تداخلی در شبکه ایجاد نشود و تنها زمانی که نود اکتیو Fail شود و نود پسیو به اکتیو تبدیل شود ، آنلاین میوشد. هر سه Second Adapter یک شبکه Private که به آن VCHA Network میگوییم تشکیل میدهند . این شبکه از Management Network مجزا است و این 3 نود میتوانند آی پی داشته باشند تا با هم ارتباط داشته باشند . این ارتباط میتواند Layer3 یا Layer2 باشد. سرور vCenter شامل یک دیتابیس و یک فایل سیستمی که حاوی تنظیمات ، گواهینامه ها و …. است . پس نیاز داریم این دو دسته از اطلاعات را به نود Passive منتقل کنیم ، درنتیجه به یک Replication نیاز است. برای Replicate دیتابیس از مکانیزم Sync و برای فایل سیستمی از مکانیزم Async استفاده میشود. وقتی نود Active دچار یک Failure شود ، اینترفیس نود Passive آنلاین میشود . از طریق ARP به شبکه اعلام میکند که از این لحظه به عنوان نود اکتیو عمل میکند و Ownership اطلاعات IP و MAC نود اکتیو را میگیرد . بعد از این اتفاق ما دو انتخاب داریم : نود Fail شده را Troubleshoot کنیم و دوباره نود را انلاین کنیم ،درنتیجه Replication به روال قبل ادامه میابد . اما اگر نتوانیم دوباره آنرا اکتیو کنیم ، در تنظیمات VCHA میتوانیم ، در vCenter ماشین قبلی را حذف و نود جدید را دوباره Redeploy کنیم ، تمام این عملیات non-disruptive میباشد. حال اگر نود Witness دچار Fail شود چه ؟ از دست دادن Witness برای vCenter Server Instance به صورت non-disruptive میباشد اما کلاستر در حالت Degraded State میرود. پس برای اینکه کلاستر به صورت سلامت عمل کند هر 3 نود باید آنلاین و به صورت سالم وجود داشته باشند. و هرکدام از نود های Passive یا Witness مشکل داشته باشند ، کلاستر در حالت Degraded State میرود و در این حالت Automatic Failover از نود Active به Passive انجام نخواهد شد و این این امر به منظور جلوگیری از وجود دو نود فعال در کلاستر میباشد. وقتی درمورد PSC و VCHA صحبت میکنیم ، ابتدا باید تصمیم بگیرید که آیا از Enhanced linked mode استفاده میکنید؟ اگر پاسخ شما مثبت است ، در نسخه 6.5 شما باید از External PSC استفاده کنید. پس اگر از External PSC استفاده میکنیم ، به یک Load balancer نیاز داریم . دلیل این امر این است که وقتی VCHA داریم ، نود اکتیو به صورت مشخص به PSC متصل باشد ، وقتی PSC دچار مشکل شود ، ما باید به صورت دستی آنرا به PSC دیگر متصل کنیم وقتی اینکار را انجام دهیم ، مکانیزم Repoint به نود Passive ما Replicate نمیشود ، پس آن نود همچنان به PSC ای که Fail شده اشاره میکند . پس اگر نود Active Fail شود و نود Passive به Active تبدیل شود به مشکل برخواهیم خورد. حالا سوال اصلی اینجاست ، چرا سرور vCenter را Highly available میکنیم اما Platform services controller را نه ؟! با کمک روش ذکر شده در مثال بالا ما هر دو اینها را Highly available میکنیم و در آن زمان است یک راه حل کامل را ارائه کرده ایم. در مقالات بعدی سعی خواهد شد مطالب عمیق تری درباره این ویژگی برای شما توضیح داده شود ، پس همراه ما باشید ….
:: برچسب ها :
حفاظت از سرورvCenter با VCHA,
VCHA چیست,
قابلیت VCHA,
حفاظت از سرور vCenter با VCHA,
تنظیمات PSC,
ن : محمد
ت : چهارشنبه 3 مرداد 1397
|
|
Veeam Backup & Replication یک برنامه پشتیبانی و محافظت از داده هاست که برای محیط های مجازی VMware vSphere و Microsoft Hyper-V hypervisors توسط شرکت Veeam ساخته شده است.این نرم افزار قابلیت پشتیبان گیری ، replication و Restore کردن ، برای ماشین های مجازی ارائه نموده است.
عملکرد:
Veeam Backup & Replication
برای محیط های
مجازی سازی
شده طراحی گردیده است. به وسیله snapshots گرفتن از ماشین ها و استفاده از این snapshots برای گرفتن بکاپ که به دو صورت Full و Incremental است. برای بازگردانی داده ها می توان نسخه پشتیبان گرفته شده را در محل ذخیره شده قبلی یا در مکانی دیگر بازیابی نمود .
گرفتن Snapshots به وسیله VMware vSphere میتواند بار سنگینی بر عملکرد ماشین های مجازی بگذارد و مدیران IT را به چالش بکشد.Veeam به طرز چشمگیری این روند را بهبود بخشیده است.با استفاده از Snapshots گرفتن در سطح استوریج حتی در ساعات کاری با کمترین تاثییر بر عملکرد می توانید از داده های خود بکاپ تهیه نمایید.Veeam می تواند با ادغام با replication در سطح استوریج در صورتی که استوریج اصلی در دسترس نباشد و دچار مشکل شده باشد به سرعت داده شما را بازیابی نماید.
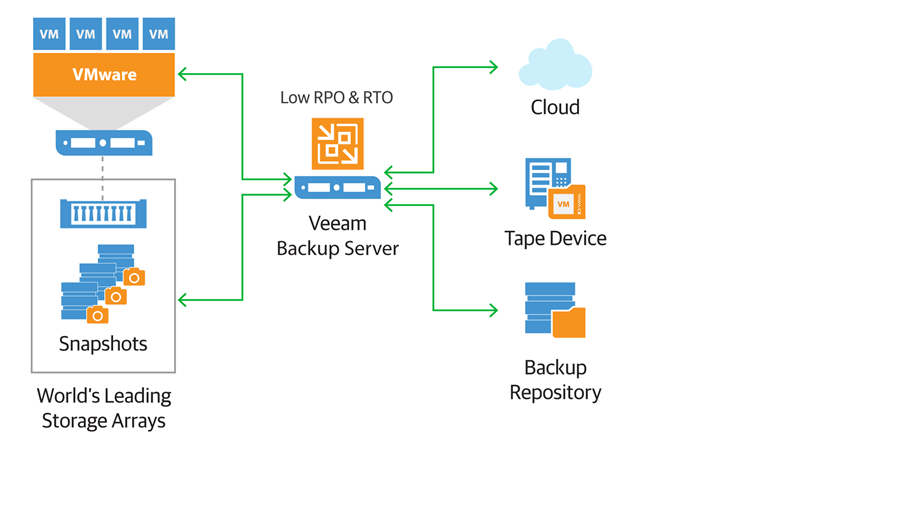
Storage partners for every business
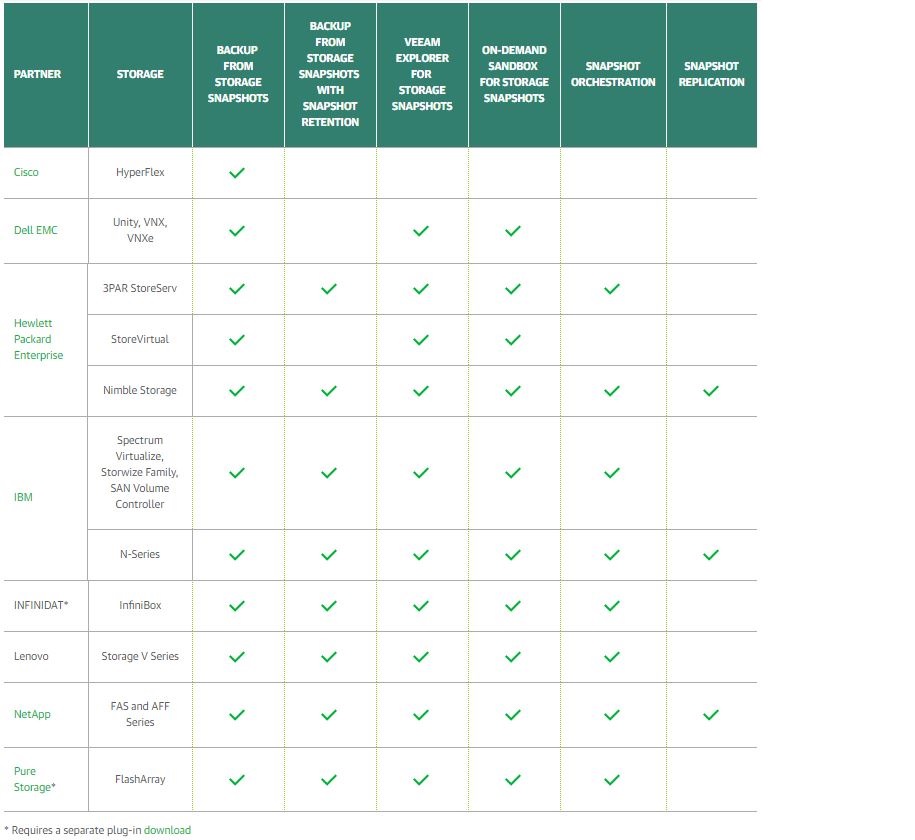
در زیر لیست شرکت های تولید کننده استوریج که از Veeam Backup & Replication پشتیبانی نموده، آورده شده است. به وسیله این استوریج ها می توان سریع تر نسخه پشتیبانی از ماشین ها را تهیه نمود و سرعت باز گردانی اطلاعات را افزایش داد.
Recovery
نرم افزار veeam backup
برای بازگردانی اطلاعات انتخاب های مختلفی را به کاربران ارائه می دهد.
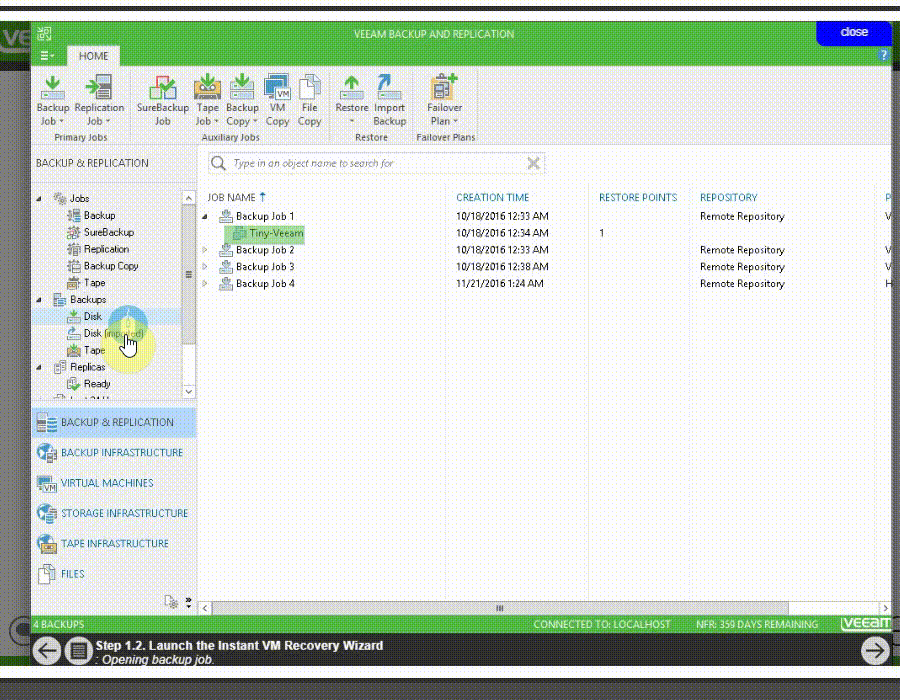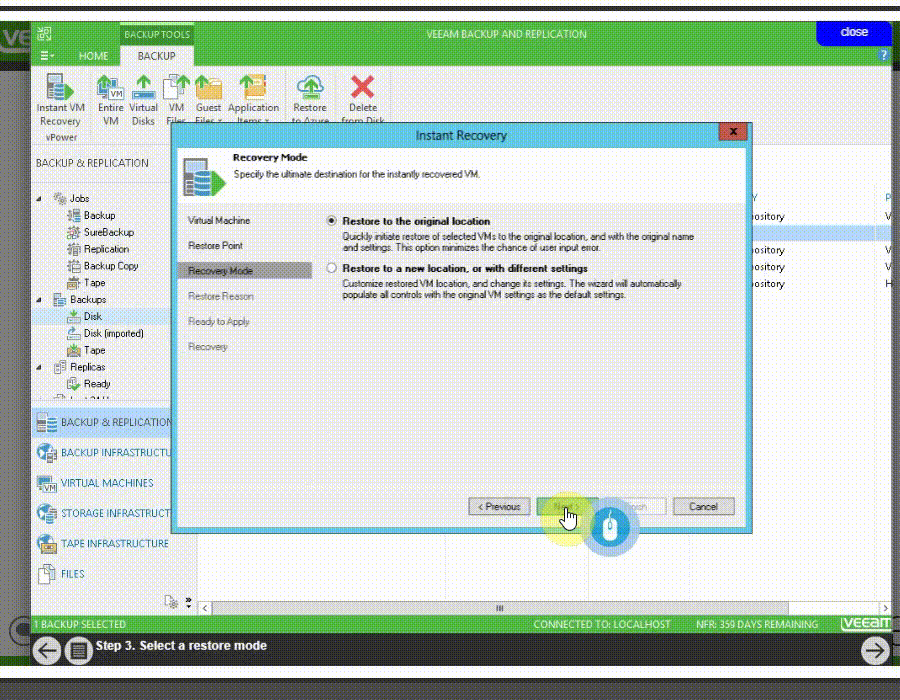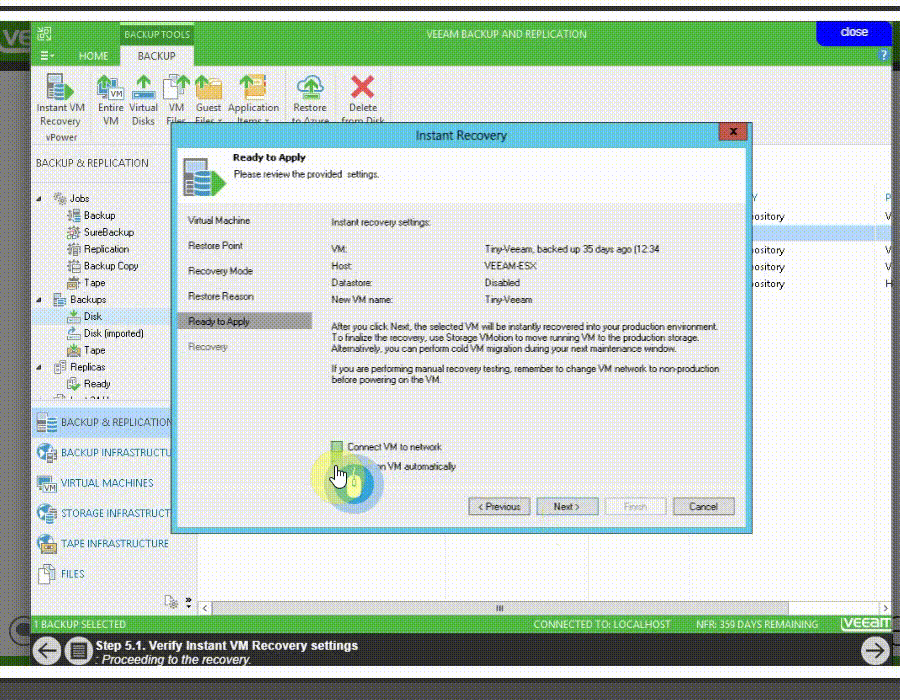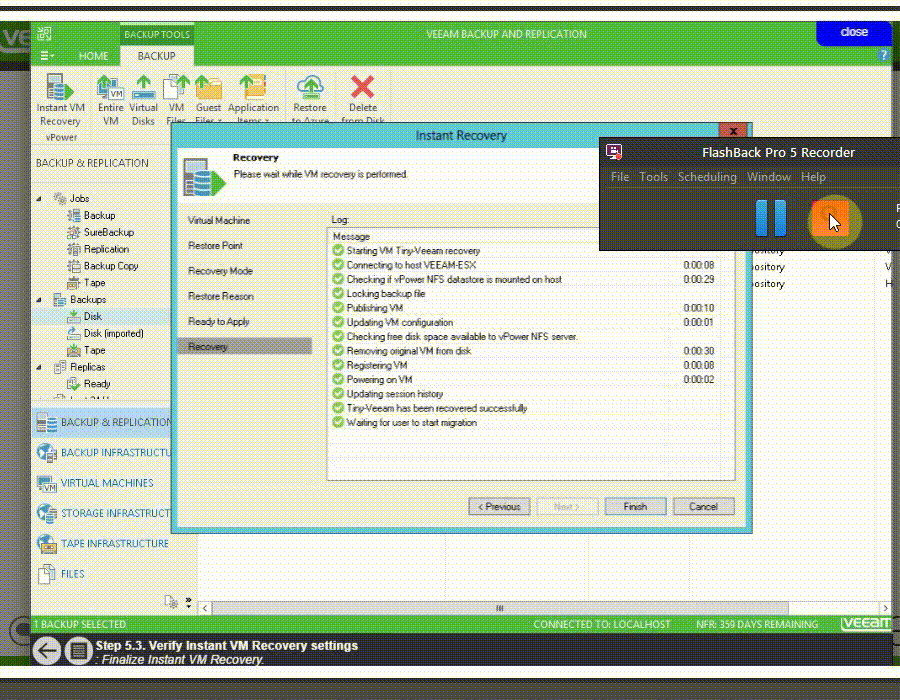
Instant VM Recovery
به وسیله Instant VM Recovery کاربران veeam backup می توانند ماشین هایی که از آن بکاپ تهیه نموده اند را به سرعت در محل ذخیره بکاپ بالا بیاورند.
Full VM Recovery
به وسیله Full VM Recovery میتوانید آخرین وضعیت ماشین ها را در بازه های مشخص زمانی در هاست اصلی یا هاست دیگر، بازیابی نمایید. VM رامی توان در مکان اصلی که از آن بکاپ گرفته شده است ، در صورتی که آن ماشین خاموش باشد یا پاک شده باشد بازیابی نمود. و یا بازیابی در هاست جدید صورت گیرد که در این صورت تنظیمات ماشین باید قابل دسترسی باشد. (تنظیمات شبکه ، دیتا سنتر)
VM File Recovery
به وسیله Instant File-Level Recovery (IFLR) شما می توانید هر فایل مورد نظرتان را در بازه زمانی مشخص بازیابی نمایید. همچنین veeam از فایل سیستم های ویندوزی و لینوکسی پشتیبانی می نماید.
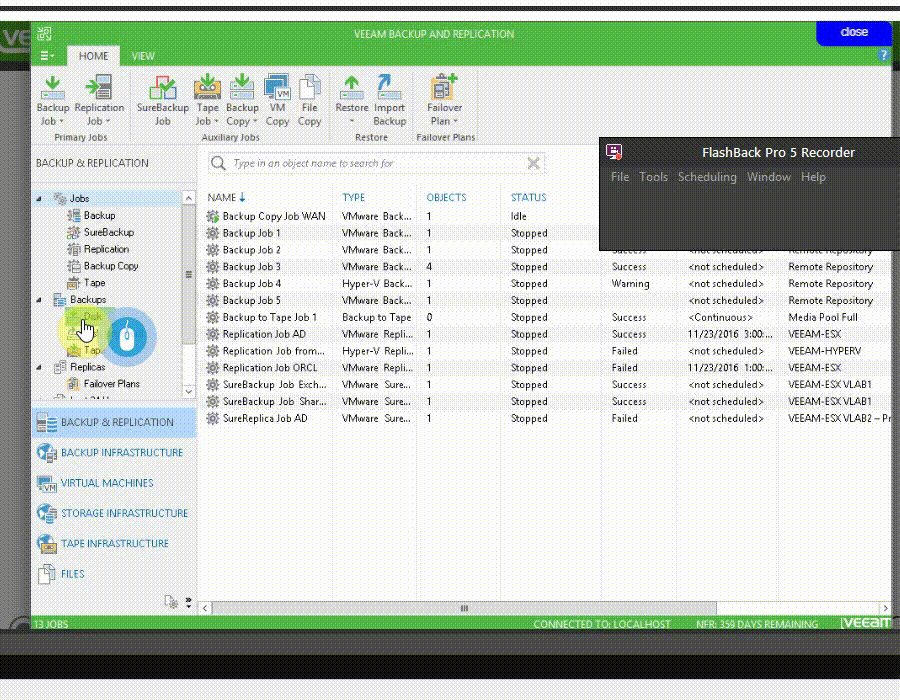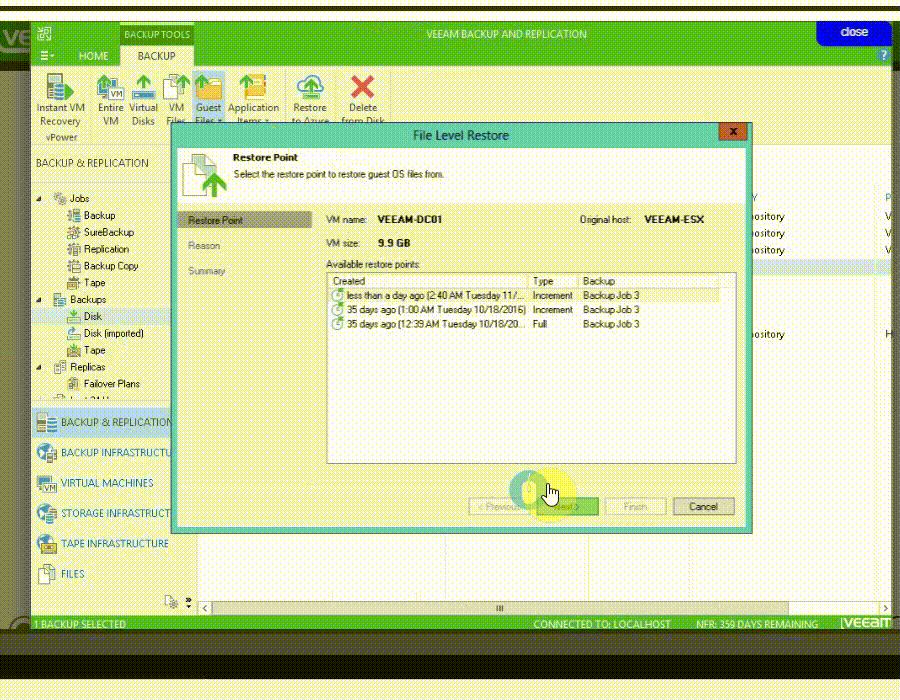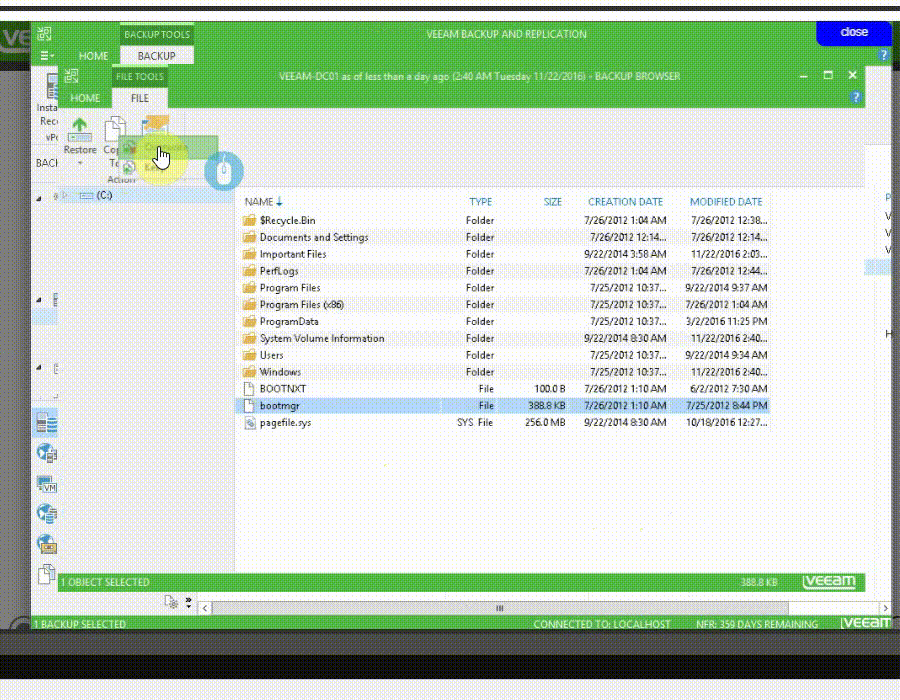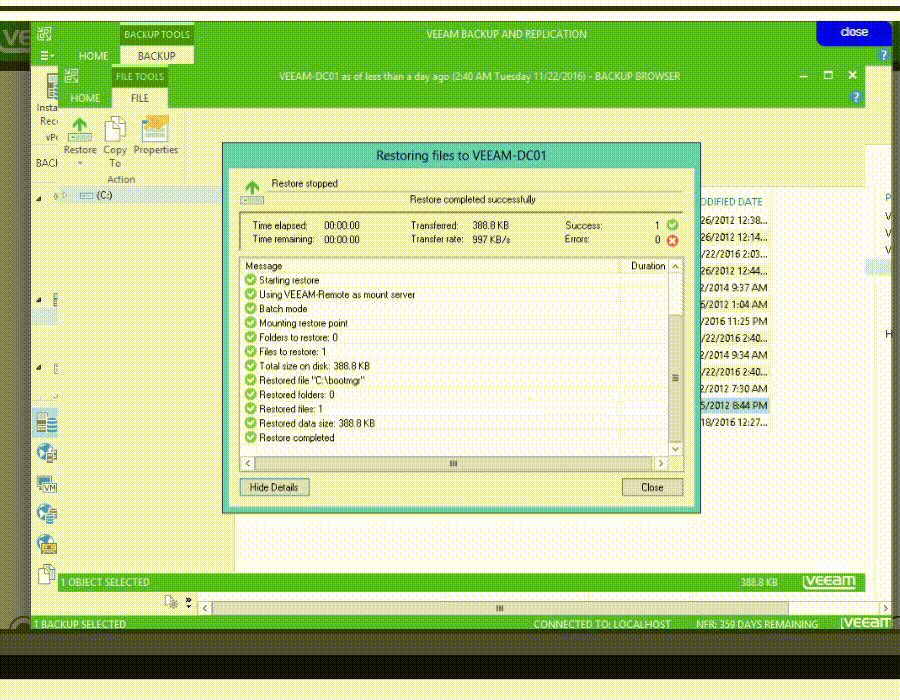
وحتی می توانید فایل های ماشین را مانند VMDK را بازگردانی نمایید.
Application-item recovery:
با استفاده از veeam backup می توانید به صورت مستقیم برای بازیابی Application های زیر استفاده نمایید.
Microsoft Active Directory
Microsoft Exchange
Microsoft SharePoint
Microsoft SQL Server
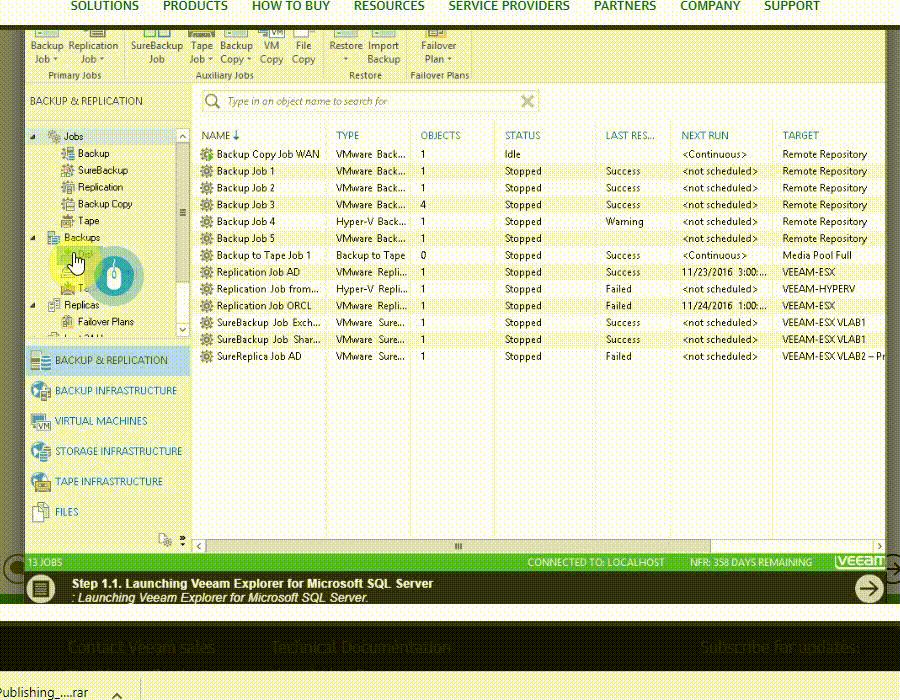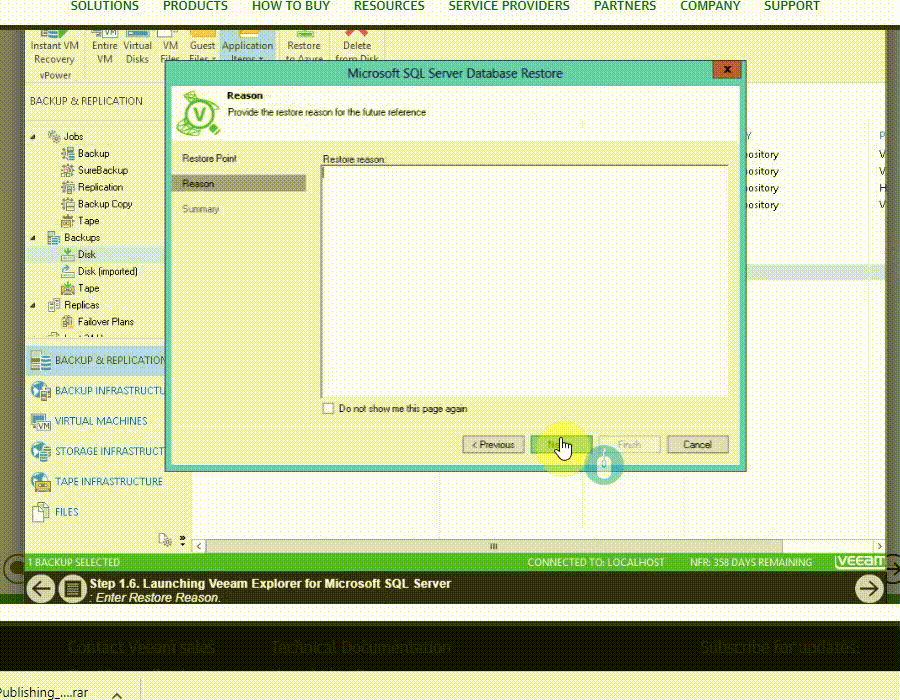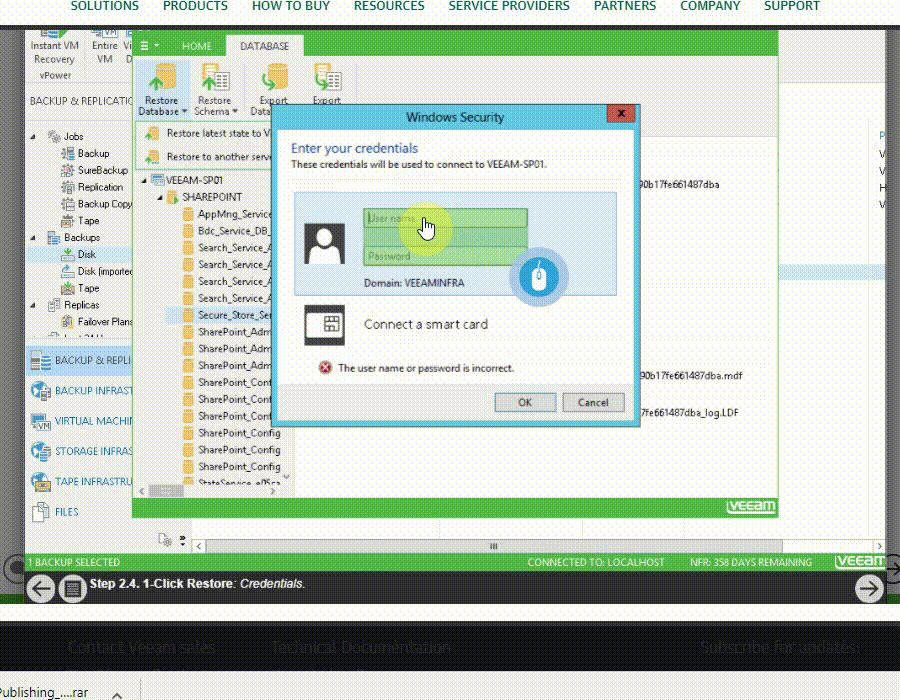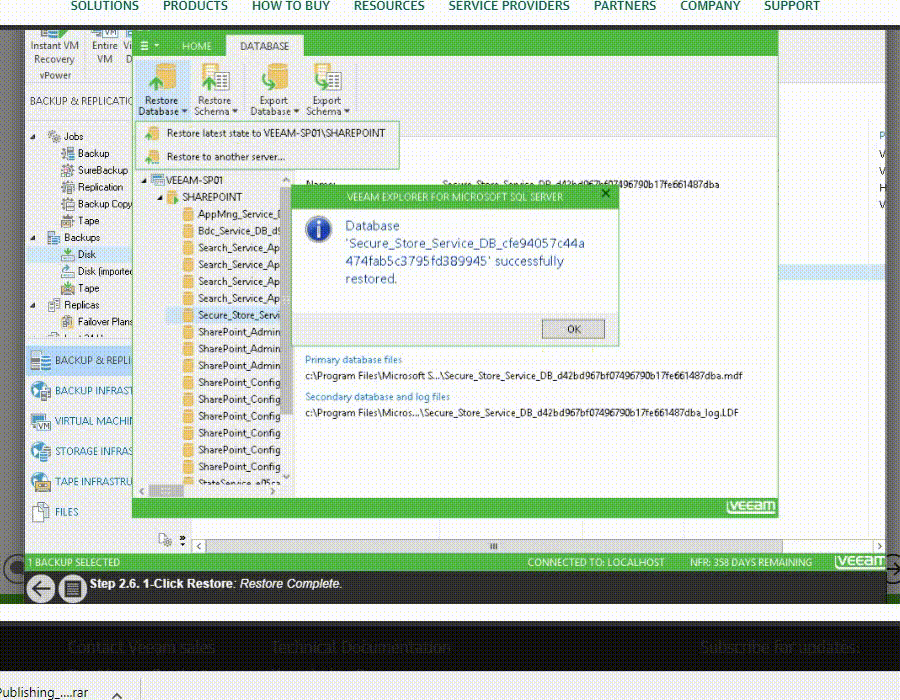
Oracle
با توجه به مختصر توضیحات بالا و با استناد به گزارش سال 2017 از Gartner ، veeam backup and replication توانسته جز 5 شرکت پیشرو در صنعت بکاپ و ریکاوری باشد.
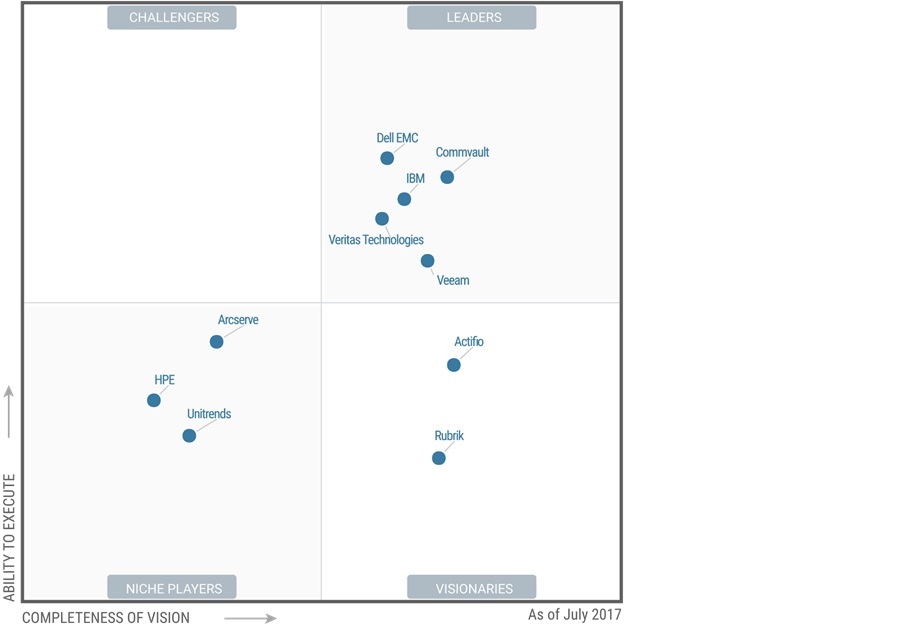
در زیر نقاط قوت و ضعف آن را مشاهده می کنید که توسط Gartner اعلام شده است:
نقاط قوت:
Veeam قابلیت های بسیاری با گزینه های بازیابی ساده برای محیط VMware و Hyper-V ارائه نموده است.
برای چندمین سال پیاپی یکی از سریع ترین شرکت های در حال رشد در صنعت پشتیباتی بوده است.
نقاط ضعف:
بسیاری از مشتریان به این نکته اشاره کرده اند که سیاست قیمت گذاری لایسنس اغلب دیگر رقابتی نیست در حالی که مدیریت و ریکاوری در Veeam ساده می باشد. اندازه مناسب برای ذخیره سازی بکاپ و پیکربندی در مرحله نصب ممکن است توجه بیشتری نیاز داشته باشد زیرا نرخ تغییرات در ماشین های مجازی بسیار بالا می باشد.
Veeam فقط به طور رسمی اعلام نموده است که از سرور فیزیکی پشتیبانی می کند ولی هنوز به طور کامل این ویژگی را ادغام و اثبات ننموده است .
نتیجه گیری:
امروزه تداوم کسب و کار معنای جدیدی به خود گرفته است . زمانی که داده ها به عنوان منبع حیاتی کسب و کار شما است حفظ اطلاعات شما و اطمینان از صحت و در دسترس بودن آن یک اولویت است. به دلیل کاهش سرور های فیزیکی و افزایش ماشین های مجازی مدیران فناوری اطلاعات با یک سری جدید از مسائل محافظت از داده ها و چالش های پشتیبانی مواجه شده اند.این چیزی بیش از یک کپی از فایل های مهم است. وضعیت هر VM نیز باید محافظت شود و به راحتی قابل دسترس باشد. هر سازمان باید نیاز های بکاپ گیریش را در چهارچوب زیر ساخت مجازی مجددا ارزیابی نماید و سپس مناسب ترین فن اوری ها را برای ارائه بهتر محافظت از داده ها انتخاب کند. Veeam با توجه به ویژگی هایی که برای محیط مجازی ارائه نموده است می تواند یکی از بهترین انتخاب ها برای محیط مجازی باشد.
:: برچسب ها :
معرفی Veeam Backup,
آموزش Veeam Backup,
نرم افزار veeam backup,
Veeam Backup چیست,
ن : محمد
ت : شنبه 30 تير 1397
|
|
Spanning Tree Protocol سوئیچ های سیسکو با استفاده از
پروتکل STP، از به وجود آمدن loop در شبکه جلوگیری می کنند. در یک LAN که دارای مسیر های redundant می باشد، اگر پروتکل STP فعال نباشد، باعث به وجود آمدن یک loop نامحدود در شبکه می شود. اگر در همان LAN پروتکل STP را فعال کنید، سوئیچ ها برخی از پورت ها را بلاک می کنند و اجازه نمی دهند اطلاعات از آن پورت ها عبور کنند. پروتکل STP با توجه به دو معیار پورت ها را برای بلاک کردن انتخاب می کند: • تمامی deviceهای موجود در LAN بتوانند با هم ارتباط برقرار کنند. درواقع STP تعداد پورت های کمی را بلاک می کند تا LAN به چند بخش که نمی توانند با هم ارتباط برقرار کنند، تقسیم نشود. • Frame ها بعد از مدتی drop می شوند و به طور نامحدود در loop قرار نمی گیرند. پروتکل STP تعادلی را در شبکه به وجود می آورد بطوریکه frame ها به هر کدام از device ها که لازم باشد می رسند بدون اینکه مشکلات loop به وجود آید. پروتکل STP با چک کردن هر interface قبل از اینکه از طریق آن اطلاعات ارسال کند، از به وجود آمدن loop جلوگیری می کند. در این روند چک کردن اگر آن پورت داخل VLAN خود در وضعیت STP forwarding باشد، از آن پورت در حالت عادی استفاده می کند، اما اگر در وضعیت STP blocking باشد، ترافیک تمام کاربران را بلاک می کند و هیچ ترافیکی در آن VLAN را از آن پورت عبور نمی دهد. توجه کنید که وضعیت STP یک پورت، اطلاعات دیگر مربوط به پورت را تغییر نمی دهد. برای مثال با تغییر وضعیت خود تغییری در وضعیت trunk/access و connected/notconnect ایجاد نمی کند. وضعیت STP یک مقدار جدا از وضعیت های قبلی دارد و اگر در حالت بلاک باشد پورت را از پایه غیر فعال می کند. نیاز به پروتکل STP پروتکل STP از وقوع سه مشکل رایج در LANهای Ethernet جلوگیری می کند. در نبود پروتکل STP ، بعضی از frame های Ethernet برای مدت زیادی (ساعت ها، روز ها و حتی برای همیشه اگر deviceهای LAN و لینک ها از کار نیوفتند) در یک loop داخل شبکه قرار می گیرند. سوئیچ های سیسکو به طور پیش فرض پروتکل STP را اجرا می کنند. توصیه می کنیم پروتکل STP را تا زمانی که تسلط کامل به آن ندارید، غیر فعال نکنید. اگر یک frame درloop قرار بگیرد Broadcast storm به وجود می آید. Broadcast storm زمانی به وجود می آید که هر نوعی از frameهای Ethernet (مانند multicast frame،broadcast frame و unicast frameهایی که مقصدشان مشخص نیست) در loop بی نهایت داخل LAN قرار بگیرند. Broadcast stormها می توانند لینک های شبکه را با کپی های به وجود آمده از یک frame اشباع کنند و باعث از بین رفتن frameهای مفید شوند، و نیز با توجه به بار پردازشی مورد نیاز برای پردازش broadcast frameها، تاثیر قابل ملاحظه ای روی عملکرد deviceهای کاربران دارند. تصویر 1-2 یک مثال ساده از Broadcast storm را نشان می دهد که در آن سیستمی که Bob نام دارد یک broadcast frame ارسال می کند. خط چین ها نحوه ارسال frameها توسط سوئیچ ها را در نبود STP نمایش می دهند. در تصویر 1-2، frameها در جهت های مختلفی می چرخند، برای ساده تر شدن مثال فقط در یک جهت آنها را نمایش داده ایم. در مفاهیم سوئیچ، سوئیچ ها در ارسال کردن broadcast farmeها، frameها را به تمام پورت ها به جز پورت فرستنده آن frame، ارسال می کنند. در تصویر 1-2، سوئیچ SW3، frame را به سوئیچ SW2 ارسال می کند، سوئیچ SW2 آن را برای سوئیچ SW1 ارسال می کند، سوئیچ SW1 نیز آن را برای SW3 ارسال می کند و به همین ترتیب این frame به سوئیچ SW2 ارسال می شود و داخل یک loop می چرخد. زمانی که یک Broadcast storm اتفاق می افتد، frame ها مانند مثال بالا به چرخیدن ادامه می دهند تا زمانی که تغییراتی به وجود آید (شخصی یکی از پورت ها را خاموش کند، سوئیچ را reload کند یا کاری کند که loop از بین برود). Broadcast storm همچنین باعث به وجود آمدن مشکل نا محسوسی به نام MAC table instability یا ناپیوستگی جدول مک می شود. MAC table instability بدین معنا است که جدول مک آدرس پیوسته در حال تغییر کردن می باشد، و علت آن این است کهframe هایی با مک آدرس یکسان از پورت های مختلفی وارد سوئیچ ها می شوند. به مثال زیر توجه کنید: در تصویر 1-2 در ابتدا سوئیچ SW3 مک آدرس باب را که از طریق پورت Fa0/13 وارد سوئیچ شده، به جدول مک آدرس خود اضافه می کند: 0200.3333.3333 Fa0/13 VLAN 1 حالا فرایند switch learning را در نظر بگیرید در زمانی که frame در حال چرخش از سوئیچSW3 به سوئیچ SW2 ، سپس به سوئیچ SW1 و بعد از آن از طریق پورت G0/1 وارد سوئیچ SW3 می شود. سوئیچ SW3 می بیند که مک آدرس مبداء 0200.3333.3333 می باشد و از پورت G0/1 وارد سوئیچ شده است، جدول مک آدرس خود را به روز می کند: 0200.3333.3333 G0/1 VLAN 1 در این مورد سوئیچ SW3 هم دیگر نمی تواند به درستی frameها را به مک آدرس باب برساند. اگر در این حالت یک frame (خارج از frameهایی که در داخل loop افتاده اند) به سوئیچ SW3 برسد که مقصد آن باب باشد، سوئیچ SW3 اشتباها frame را روی پورت G0/1 به سوئیچ SW1 ارسال می کند، که این موضوع ترافیک زیادی را به وجود می آورد. سومین مشکلی که Frame های در حال چرخش در یک broadcast storm ایجاد می کنند این است که کپی های مختلفی از یک frame به دست گیرنده می رسد. در تصویر 1-2 فرض کنید که باب یک frame را برای لاری ارسال کند در حالی که هیچ کدام از سوئیچ ها مک آدرس لاری را نمی دانند. سوئیچ ها frameها را به صورت unicast هایی که مک آدرس مقصدشان مشخص نیست، ارسال می کنند. زمانی که باب یک frame که مک آدرس مقصدش لاری است را ارسال می کند، سوئیچSW3 یک کپی از آن را به سوئیچ های SW1 و SW2 ارسال می کند. سوئیچ های SW1 و SW2 نیز frame را broadcast می کنند، این کپی ها باعث می شود که آن frame در داخل یک loop قرار گیرد. سوئیچ SW1 همچنین یک کپی از frame را به پورت Fa0/11 برای لاری ارسال می کند. در نتیجه لاری کپی های مختلفی از آن frame را دریافت می کند، که می تواند باعث از کار افتادن برنامه ای در سیستم لاری و یا مشکلات شبکه ای شود. جدول زیر خلاصه ای از سه مشکل اساسی در شبکه ای که دارای redundancy است و STP در آن اجرا نمی شود را نشان می دهد: پروتکل (STP (IEEE 802.1D دقیقا چه کار می کند؟ پروتکلSTP با قرار دادن هر یک از پورت های سوئیچ در وضعیت های forwarding و blocking از به وجود آمدن loop جلوگیری می کند. پورت هایی که در وضعیت forwarding هستند به صورت عادی فعالیت می کنند، frameها را ارسال و دریافت می کنند. اما پورت هایی که در وضعیت blocking قرار دارند به جز پیام های مربوط به پروتکل STP (و برخی دیگر از پیام هایی که برای پروتکل ها استفاده می شوند) ، هیچ frame دیگری را پردازش نمی کنند. این پورت ها frameهای کاربران را ارسال نمی کنند، مک آدرس frameهای ورودی را ذخیره نمی کنند و frameهای دریافتی از کاربران را نیز پردازش نمی کنند. تصویر 2-2 راه حل استفاده از پروتکل STP (قرار دادن یکی از پورت های سوئیچ SW3 در وضعیت blocking) در مثال پیشین را نمایش می دهد: همانطور که در مراحل زیر نشان داده شده، زمانی که باب یک broadcast را ارسال می کند، دیگر loop به وجود نمی آید: • مرحله اول: باب frame را به سوئیچ SW3 ارسال می کند. • مرحله دوم: سوئیچ SW3 این frame را فقط به سوئیچ SW1 ارسال می کند، دیگر به سوئیچ SW2 ارسال نمی شود چون پورت G0/2 در وضعیت blocking قرار دارد. • مرحله سوم: سوئیچ SW1 این frame را روی پورت های Fa0/12 و G0/1 ارسال می کند. • مرحله چهارم: سوئیچ SW2 این frame را روی پورت های Fa0/12 و G0/1 ارسال می کند. • مرحله پنجم: سوئیچ SW3 به صورت فیزیکی یک frame را دریافت می کند، اما frame دریافتی از SW2 را به دلیل اینکه پورت G0/2 در سوئیچ SW3 در وضعیت blocking قرار دارد، نادیده می گیرد. با استفاده از توپولوژی STP در تصویر 2-2، سوئیچ ها از لینک موجود بین SW2 و SW3 برای انتقال ترافیک استفاده نمی کنند. با این حال، اگر لینک بین SW3 و SW1 دچار مشکل شود، پروتکل STP پورت G0/2 را از وضعیت blocking به وضعیت forwarding تغییر می دهد و سوئیچ ها می توانند از آن لینکredundant استفاده کنند. در این موقعیت ها پروتکل STP با انجام فرایند هایی متوجه تغییرات در توپولوژی شبکه می شود و تشخیص می دهد که پورت ها نیاز به تغییر در وضعیتشان دارند و وضعیت آن ها را تغییر می دهد. سوالاتی که احتمالا زهن شما را نیز مشغول کرده: پروتکل STP چگونه پورت ها را برای تغییر وضعیت انتخاب می کند و چرا این کار را می کند؟ چگونه وضعیت blocking را برای بهره مندی از مزایای لینک های redundant، به وضعیت forwarding تغییر می دهد؟ در ادامه به این سوالات پاسخ خواهیم داد. پروتکل STP چگونه کار می کند؟ الگوریتم STP یک درخت پوشا (spanning tree) از پورت هایی که frameها را ارسال می کنند تشکیل می دهد. این ساختار درختی، مسیرهایی را برای رسیدن لینک های ethernet به هم مشخص می کند. (مانند پیمودن یک درخت واقعی که از ریشه درخت شروع می شود و تا برگ ها ادامه دارد) توجه: STP قبل از اینکه در سوئیچ های LAN استفاده شود، در Ethernet bridgeها به کار رفته بود. STP از فرایندی که بعضا spanning-tree algorithm)STA) نامیده می شود، استفاده می کند که در آن پورت هایی که باید در وضعیت forwarding قرار بگیرند را انتخاب می کند. STP پورت هایی که برای forwarding انتخاب نشدند را در وضعیت blocking قرار می دهد. در واقع پروتکل STP پورت هایی که در ارسال کردن اطلاعات باید فعال باشند را انتخاب می کند و پورت های باقی مانده را در وضعیت blocking قرار می دهد. پروتکل STP برای قرار دادن پورت ها در حالت forwarding از سه مرحله استفاده می کند: • پروتکل STP یک سوئیچ را به عنوان root انتخاب می کند و تمام پورت های فعال در آن سوئیچ را در وضعیت forwarding قرار می دهد. • در هر کدام از سوئیچ های nonroot (همه ی سوئیچ ها به جز root)، پورتی که کمترین هزینه را برای رسیدن به سوئیچ root دارد (root cost)، به عنوان root port(RP) انتخاب می کند و آن ها را در وضعیت forwarding قرار می دهد. • تعداد زیادی سوئیچ می توانند به یک بخش از Ethernet متصل شوند، اما در شبکه های مدرن، معمولا دو سوئیچ به هر لینک (بخش) متصل می شوند. در بین سوئیچ هایی که به یک لینک مشترک متصل هستند، پورت سوئیچی که root cost کمتری دارد در وضعیت forwarding قرار می گیرد. این سوئیچ ها را designated switch می نامند و پورت هایی که در وضعیت forwarding قرار گرفته را designated port)DP) می نامند. باقی پورت ها در وضعیت blocking قرار می گیرند. خلاصه ای از علت قرار گرفتن پورت ها در وضعیت های blocking و forwarding توسط پورتکل STP Bridge و Hello BPDU فرایند STA با انتخاب یک سوئیچ به عنوان root شروع می شود. برای اینکه روند انتخاب را بهتر متوجه شوید، شما باید با مفهوم پیام هایی که بین سوئیچ ها تبادل می شود به خوبی آشنا شوید و با فرمت شناساگری که برای شناسایی هر سوئیچ استفاده می شود آشنا باشید. (STP bridge ID (BID یک مقدار 8 بایتی برای شناسایی هر سوئیچ می باشد. Bridge ID به دو بخش 2 بایتی که مشخص کننده اولویت و حق تقدم است و 6 بایتی که system ID نامیده می شود و همان مک آدرس هر سوئیچ است، تقسیم می شود. استفاده از مک آدرس این اطمینان را می دهد که bridge ID هر سوئیچ یکتا خواهد بود. پیام هایی که برای تبادل اطلاعات مربوط به پروتکل STP بین سوئیچ ها استفاده می شود، bridge protocol data units )BPDU) نام دارد. رایج ترین BPDU ، که hello BPDU نام دارد، تعدادی از اطلاعات که شامل BID سوئیچ ها نیز می شود را لیست می کند و ارسال می کند. با استفاده از BID درج شده روی هر پیام، سوئیچ ها می توانند تشخیص دهند که هر پیام Hello BPDU از طرف کدام سوئیچ است. جدول زیر اطلاعات کلیدی مربوط به Hello BPDU را نشان می دهد: انتخاب سوئیچ root سوئیچ ها با استفاده از BIDهای موجود در پیام های BPDU، سوئیچ root را انتخاب می کنند. سوئیچی که عدد BID آن مقدار کمتری را داشته باشد به عنوان سوئیچ root انتخاب می شود. با توجه به اینکه بخش اول عدد BID مقدار اولویت می باشد، سوئیچی که مقدار اولویت پایین تری داشته باشد به عنوان سوئیچ root انتخاب می شود. برای مثال اگر سوئیچ های اول و دوم به ترتیب دارای اولویت های 4096 و 8192 باشند، بدون در نظر گرفتن مک آدرس سوئیچ ها که در به وجود آمدن BID هر سوئیچ موثر است، سوئیچ اول به عنوان سوئیچ root انتخاب خواهد شد. اگر مقدار اولویت دو سوئیچ برابر شد، سوئیچی که مک آدرس آن مقدار کمتری را داشته باشد به عنوان سوئیچ root انتخاب می شود. در این حالت به علت یکتا بودن مک آدرس، حتما یک سوئیچ انتخاب خواهد شد. پس اگر مقدار اولویت دو سوئیچ برابر باشد و مک آدرس آنها 0200.0000.0000 و 0911.1111.1111 باشد، سوئیچی که دارای مک آدرس 0200.0000.0000 است، به عنوان سوئیچ root انتخاب می شود. مقدار اولویت مضربی از 4096 است و به صورت پیش فرض برای همه ی سوئیچ ها مقدار 32768 را دارد. از آنجایی که مک آدرس سوئیچ ها معیار مناسبی برای انتخاب سوئیچ root نمی باشد بهتر است به صورت دستی مقدار اولویت را تغییر دهیم تا سوئیچی که می خواهیم به عنوان سوئیچ root انتخاب شود. در فرایند انتخاب سوئیچ root، سوئیچ ها از طریق فرستادن پیام های Hello BPDU که BID خود را در این پیام ها به عنوان root BID قرار داده اند، سعی می کنند خود را به عنوان سوئیچ root به سوئیچ های مجاور خود معرفی کنند. اگر یک سوئیچ پیامی را دریافت کند که BID کمتری نسبت به BID خودش داشته باشد، آن سوئیچ دیگر خود را به عنوان سوئیچ root معرفی نمی کند، به جای آن شروع به ارسال پیام دریافتی که دارای BID بهتری است می کند (مانند رقابت های انتخاباتی که یک نامزد به نفع نامزد هم حزبش که موقعیت بهتری دارد، از رقابت در انتخابات خارج می شود). در نهایت تمامی سوئیچ ها به یک نظر نهایی می رسند که کدام سوئیچ BID کمتری دارد و همه آن سوئیچ را به عنوان سوئیچ root انتخاب می کنند. توجه : در مقایسه دو پیام Hello با هم، پیامی که BID کمتری دارد، superior Hello و پیامی که BID بیشتری دارد، inferior Hello نام دارد. تصویر 3-2 آغاز فرایند انتخاب سوئیچ root را نشان می دهد، در ابتدای این فرایند SW1 همانند باقی سوئیچ ها خود را به عنوان سوئیچ root معرفی می کند. SW2 پس از دریافت Hello مربوط به SW1 متوجه می شود که SW1 شرایط بهتری را برای root بودن دارد، پس شروع به ارسال Hello دریافتی از SW1 می کند. در این حالت سوئیچ SW1 خود را به عنوان root معرفی می کند و SW2 نیز با آن موافقت می کند اما سوئیچ SW3 هنوز سعی می کند که خود را به عنوان سوئیچ root معرفی کند و Hello BPDUهای خود را ارسال می کند. دو نامزد هنوز باقی ماندند:SW1 و SW3. از آنجایی که SW1 مقدار BID کمتری دارد، SW3 پس از دریافت BPDU مربوط به SW1، SW1 را به عنوان سوئیچ root می پذیرد و به جای BPDU خود، BPDU دریافتی از SW1 را به سوئیچ های مجاور ارسال می کند. پس از اینکه فرایند انتخاب تکمیل شد، فقط سوئیچ root به تولید پیام های Hello BPDU ادامه می دهد. سوئیچ های دیگر این پیام ها را دریافت می کنند و BID فرستنده و root costرا تغییر می دهند و به باقی پورت ها ارسال می کنند. در تصویر 4-2، در قدم اول سوئیچ SW1 پیام های Hello را ارسال می کند، در قدم دوم سوئیچ های SW2 و SW3 به صورت مستقل تغییرات را روی پیام های دریافتی اعمال می کنند و آن ها را روی پورت های خود ارسال می کنند. برای اینکه بخواهیم مقایسه BID را خلاصه کنیم، BID را به بخش های تشکیل دهنده ان تقسیم می کنیم، سپس به صورت زیر مقایسه می کنیم: • اولویتی که کمترین مقدار را دارد • اگر مقدار اولویت آن ها برابر باشد، سوئیچی که مک ادرسش کمترین مقدار را دارد انتخاب Root Port برای هر سوئیچ در مرحله ی بعدی، پس از انتخاب سوئیچ root، پروتکل STP برای سوئیچ های nonroot (همه ی سوئیچ ها به جز سوئیچ root) یک root port )RP) انتخاب می کند. RP هر سوئیچ، پورتی است که کمترین هزینه را برای رسیدن به سوئیچ root دارد. احتمالا عبارت هزینه برای همه ی ما در انتخاب مسیر بهتر، روشن و مشخص باشد. اگر به دیاگرام شبکه ای که در آن سوئیچ root و هزینه ارسال اطلاعات روی هر پورت مشخص باشد توجه کنید، می توانید هزینه برقراری ارتباط با سوئیچ root را برای هر پورت به دست آورید. توجه کنید که سوئیچ ها برای به دست آوردن هزینه برقراری ارتباط با سوئیچ root، از دیاگرام شبکه استفاده نمی کنند، صرفا استفاده از آن برای درک این موضوع به ما کمک می کند. تصویر 5-2 همان سوئیچ های مثال پیشین که در آن سوئیچ root و هزینه ی رسیدن به سوئیچ root را برای پورت های سوئیچ SW3 نشان می دهد. سوئیچ SW3 برای ارسال frameها به سوئیچ root، می تواند از دو مسیر استفاده کند: مسیر مستقیم که از پورت G0/1 خارج می شود و به سوئیچ root می رسد، و مسیر غیر مستقیمی که از پورت G0/2 خارج می شود و از طریق SW2 به سوئیچ root می رسد. برای هر یک از پورت ها، هزینه ی رسیدن به سوئیچ root برابر است با مجموع هزینه ی خروج از پورت هایی که frame ارسالی، برای رسیدن به سوئیچ root از آن ها عبور می کند (در این محاسبه، هزینه ورود آن frame به پورت ها حساب نمی شود). همانطور که مشاهده می کنید، مجموع هزینه ی مسیر مستقیم که از پورت G0/1 سوئیچ SW3 خارج می شود برابر 5 است، و مسیر دیگر دارای مجموع هزینه ی 8 می باشد. از آنجایی که پورت G0/1، بخشی از مسیری است که هزینه ی کمتری برای رسیدن به سوئیچ root دارد، سوئیچ SW3 این پورت را به عنوان root port انتخاب می کند. سوئیچ ها با سپری کردن فرایندی متفاوت به همین نتیجه می رسند. آنها هزینه خروج از پورت خود را به root cost موجود در Hello BPDU ورودی از همان پورت اضافه می کنند و هزینه رسیدن به سوئیچ root از طریق آن پورت را به دست می آورند. هزینه خروج از هر پورت در پروتکل STP یک عدد صحیح (integer) می باشد که به هر پورت در هر VLAN اختصاص می یابد، تا پروتکل STP با استفاده از این مقیاس اندازه گیری بتواند تصمیم بگیرد که کدام پورت را به توپولوژی خود اضافه کند. در این فرایند سوئیچ ها، root cost سوئیچ های مجاور را که از طریق Hello BPDUهای دریافتی به دست می آورند، بررسی می کنند. تصویر 6-2 یک مثالی از چگونگی محاسبه بهترین root cost و سپس انتخاب آن به عنوان root port را نشان می دهد. اگر به تصویر توجه کنید، خواهید دید که سوئیچ root پیام هایی(Hello) که root cost آن ها برابر صفر می باشد را ارسال می کند. هزینه رسیدن به سوئیچ root از طریق پورت های سوئیچ root برابر با صفر است. در ادامه به سمت چپ تصویر توجه کنید که سوئیچ SW3، root cost دریافتی از طریق SW1 را (که برابر صفر است) با هزینه ی خروج از پورت G0/1 که آن Hello را دریافت کرده (5) جمع می کند و هزینه ارسال اطلاعات از طریق این پورت را به دست می آورد. در سمت راست تصویر، سوئیچ SW2 متوجه شده که root cost آن برابر با 4 است. پس زمانی که SW2 یک Hello برای SW3 ارسال می کند، مقدار root cost آن را 4 قرار می دهد. در سمت دیگرهزینه ارسال اطلاعات از طریق پورت G0/2 در سوئیچ SW3 برابر 4 است، از اینرو سوئیچ SW3 این دو مقدار را با هم جمع می کند و به این نتیجه می رسد که هزینه ی رسیدن به سوئیچ root از طریق پورت G0/2 برابر 8 است. با توجه به نتایج به دست آمده از آنجایی که پورت G0/1 نسبت به پورت G0/2 هزینه ی کمتری برای رسیدن به سوئیچ root دارد، پس سوئیچ SW3 پورت G0/1 را به عنوان RP انتخاب می کند. سوئیچ SW2 نیزبا گذراندن همین فرایند پورت G0/2 را به عنوان RP انتخاب می کند. سپس تمام سوئیچ ها، root port های خود را در وضعیت forwarding قرار می دهند. انتخاب Designated Port در هر LAN segment (پورت کاندید) پس از انتخاب سوئیچ root، در سوئیچ های nonroot، تمام root portها را مشخص کردیم و آنها را در وضعیت forwarding قرار دادیم. مرحله نهایی پروتکل STP برای تکمیل توپولوژی STP، انتخاب designated port در هر LAN segment است. در هر بخش(segment) از LAN، پورت سوئیچی که کمترین root cost را دارد و به آن بخش از LAN متصل است Designated port )DP) نامیده می شود. زمانی که یک سوئیچ nonroot می خواهد که یک Hello را ارسال کند، هزینه رسیدن به سوئیچ root را در root cost آن پیام قرار می دهد و ارسال می کند. دراینصورت پورت سوئیچی که کمترین هزینه را برای رسیدن به root دارد، در میان تمام سوئیچ هایی که به آن بخش متصل هستند، به عنوان DP در آن بخش شناخته می شود. در این مرحله اگر هزینه سوئیچ ها برای رسیدن به سوئیچ root برابر بود، پورت سوئیچی که BID کمتری دارد را به عنوان DP انتخاب می کنیم. در تصویر 4-2 پورت G0/1 در سوئیچ SW2 که به سوئیچ SW3 متصل است، به عنوان DP انتخاب می شود. پس از انتخاب DPها، تمام آن ها را در وضعیت forwarding قرار می دهیم. مثالی که در تصاویر 3-2 تا 6-2 به نمایش گذاشته شد، تنها پورتی که نیازی ندارد تا در وضعیت forwarding قرار بگیرد، پورت G0/2 در سوئیچ SW3 است. درنهایت فرایند پروتکل STP کامل شد و جدول زیر وضعیت نهایی هر پورت و علت قرار گرفتن در آن وضعیت را نشان می دهد: به صورت خلاصه اگر بخواهیم توضیح دهیم، در فرایند اجرای پروتکل STP: • در قدم اول سوئیچ root انتخاب می شود که ابتدا تمام سوئیچ ها سعی می کنند خود را به عنوان root معرفی کنند، سپس سوئیچی که رقم BID آن مقدار کمتری را داشته باشد به عنوان سوئیچ root انتخاب خواهد شد. • در قدم دوم برای هر سوئیچ، پورتی که کمترین هزینه برای رسیدن به سوئیچ root دارد را به عنوان root port انتخاب می شود. سپس همه ی root portها را در وضعیت forwarding قرار می گیرند. • در قدم سوم پورت های کاندید انتخاب می شوند و در وضعیت forwarding قرار می گیرند. در نهایت پورت هایی که وضعیتشان مشخص نشده در وضعیت blocking قرار می گیرند.
:: برچسب ها :
پروتکل STP,
درباره ی پروتکل STP,
کاربرد پروتکل STP,
پروتکل STP چیست,
STP چیست,
ن : محمد
ت : شنبه 30 تير 1397
|
|
معرفی vCenter Server 6.
7
vSphere 6.7معرفی شد ! و vCenter Server Appliance اکنون به صورت پیش فرض deploy میشود . این نسخه پر از پیشرفت های جدید برای vCenter Server Appliance در تمام زمینه ها است . اکنون مشتریان ابزارهای بیشتری برای کمک به مانیتورینگ دارند. vSphere Client) HTML5) پر از جریان های کاری جدید و نزدیک به ویژگی های آینده نگرانه است. معماری vCenter Server Appliance به سمت مدل پیاده سازی ساده تر حرکت می کند. همچنین File-Based backup درونی که با یک scheduler همراه است . و رابط گرافی کاربر vCenter Server Appliance که از تم Clarity پشتیبانی میکند . اینها فقط بخشی از ویژگی های جدید در vCenter Server Appliance 6.
7هستند .این مقاله به جزئیات بیشتری از پیشرفت های ذکر شده در بالا وارد خواهد شد.
Lifecycle
Install
یکی از تغییرات مهم در vCenter Server Appliance، ساده سازی معماری است . در گذشته تمام سرویس های vCenter Server در یک instance قرار داشت . اکنون میتوانیم دقیقا همان کار را با vCenter Server Appliance 6.
7انجام دهیم . vCenter Server با Embedded PSC به همراه Enhanced Linked Mode ارائه میشود. بیایید نگاهی به مزایایی که این مدل پیاده سازی ارائه می دهد بیندازیم:
- برای ایجاد high availability نیازی به load balancer نیست و به طور کامل از native vCenter Server High Availability پشتیبانی میکند .
- حذف SSO Site boundary ، پیاده سازی را با انعطاف پذیری بیشتری همراه کرده است.
- پشتیبانی از حداکثر مقیاس vSphere
- میتوانید تا 15 دامنه برای استفاده از vSphere Single Sign-On اضافه کنید
- تعداد گره ها را برای مدیریت و نگهداری کاهش می دهد
Migrate
vSphere 6.
7همچنین آخرین نسخه برای استفاده از vCenter Server برای ویندوز را داراست ، که در گذشته نبود. مشتریان می توانند با ابزار داخلی Migration Tool به vCenter Server Appliance مهاجرت کنند. در vSphere 6.7 می توانید نحوه وارد کردن داده های تاریخی و عملکرد را در هنگام Migrate انتخاب کنیم.
- Deploy & import all data
- Deploy & import data in the background
مشتریان همچنین زمان تخمین زده شده از مدت زمانی که طول میکشد تا Migrate انجام شود را میبینند . زمان تخمین زده شده بر اساس اندازه داده های تاریخی و عملکرد در محیط شما متفاوت است. در حالی که مشتریان میتوانند در زمان وارد کردن داده ها در پس زمینه عملیات را pause یا resume کنند . این قابلیت جدید در رابط مدیریت vSphere Appliance موجود است. یکی دیگر از بهبود ها پشتیبانی از پورت های custom در زمان عملیات Migrate است . مشتریانی که پورت پیش فرض Windows vCenter Server را تغیرداده اند دیگر مسدود نمیشوند.
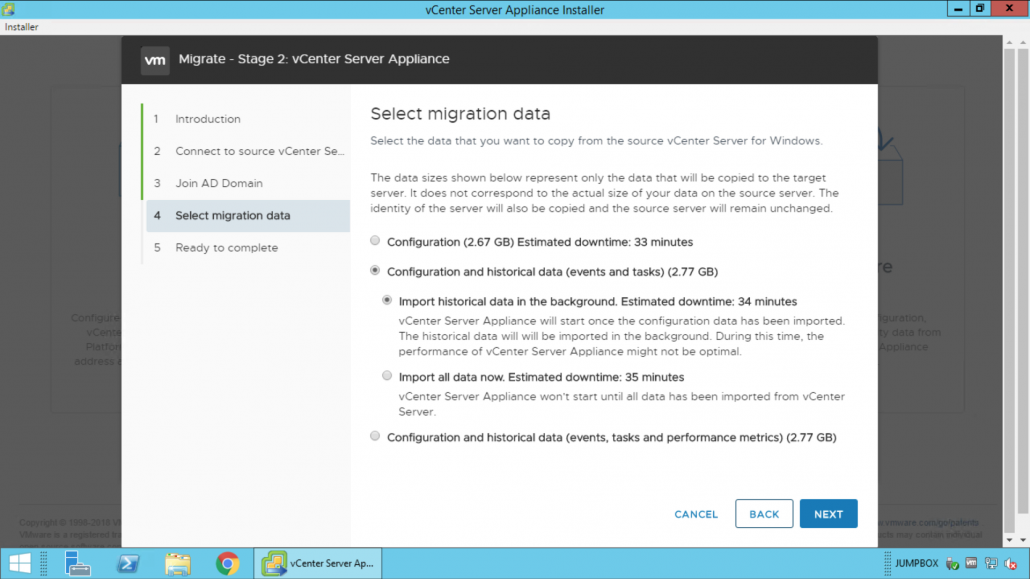
Upgrade
vSphere 6.
7فقط از upgrades یا migrations از vSphere 6.0 یا 6.5پشتیبانی میکند . vSphere 5.5 مسیر مستقیم بروزرسانی به vSphere 6.7 ندارد. مشتریانی با vSphere 5.5 باید ابتدا به vSphere 6.0 یا 6.5بروزرسانی کنند و بعد به vSphere 6.7 بروزرسانی انجام دهند . هم چنین vCenter Server 6.0 یا 6.5 که هاست ESXi 5.5 دارند نمیتوانند بروزرسانی یا migrations انجام دهند ، تا زمانی که حداقل به نسخه ESXi 6.0 یا بالاتر بروز کنند .
یادآوری: vSphere 5.5 در تاریخ September 19, 2018. به پایان پشتیبانی general میرسد.
نظارت و مدیریت
سرمایه گذاری بسیاری جهت بهبود وضعیت Monitoring در vCenter صورت گرفته است. ما شروع این بهبود را از VSphere 6.5 دیدیم و در VSphere 6.
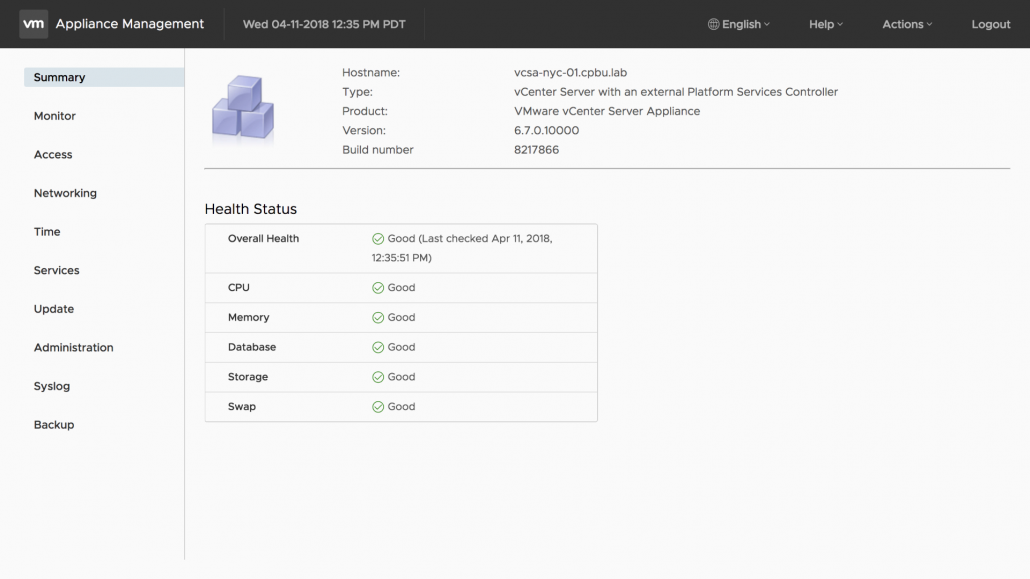
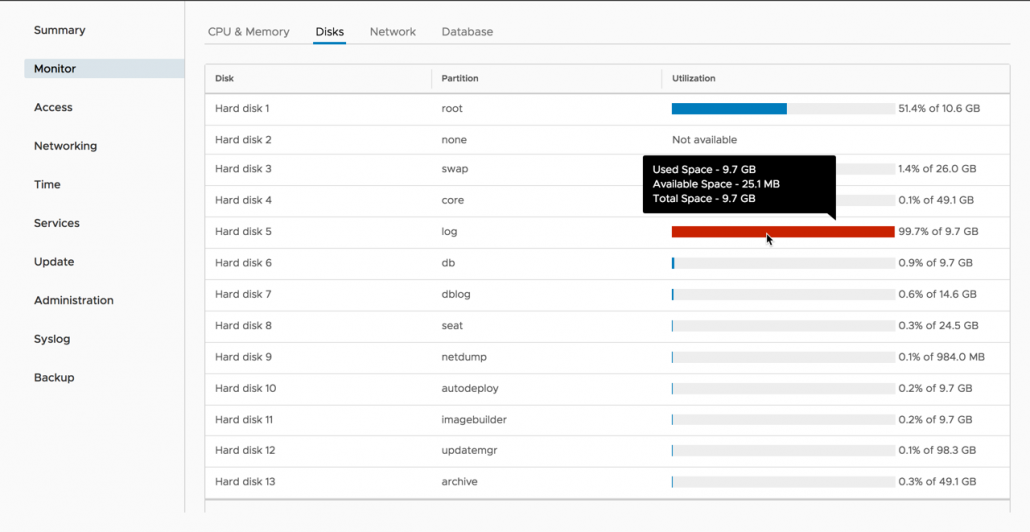
7شاهد چندین پیشرفت جدید نیز می باشیم. بیاییم به پنل مدیریتی vSphere VAMI بر روی پورت 5480 متصل شویم. اولین چیزی که مشاهده می کنیم این است که VAMI به محیط کاربری Clarity آپدیت شده است. ما همچنین می بینیم که در مقایسه با vSphere 6.5 تعدادی تب جدید در پنل سمت چپ قرار گرفته است. یک تب اختصاصی برای مانیتورینگ قرار داده شده است، که در آن ما می توانیم میزان مصرف و وضعیت سی پی یو، رم، شبکه و Database ها را مشاهده نمائیم. بخش جدیدی در تب مانیتورینگ تحت عنوان Disks قرار داده شده است. مشتریان می توانند پارتیشن هر یک از دیسک های vCenter سرور، فضای باقیمانده و مصرف شده را مشاهده نمایند.
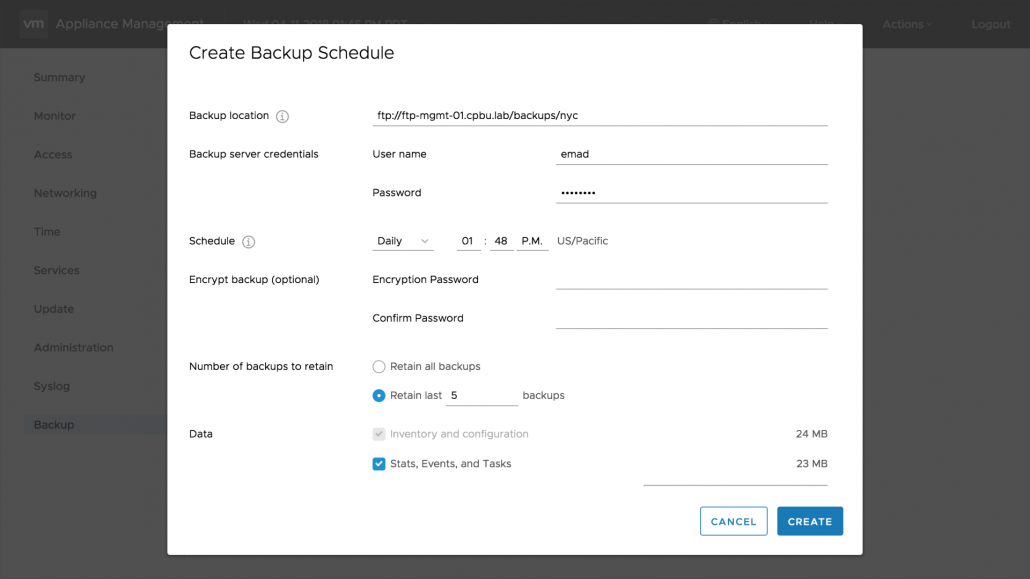
بکآپ های File-Based اولین بار در vSphere 6.5 در زیرمجموعه تب summary قرار گرفتند و اکنون تب مخصوص خود را دارند. اولین گزینه ی در دسترس در تب بکآپ تنظیم scheduler می باشد. مشتریان می توانند بکآپ های vCenter را برنامه ریزی زمانی نموده و انتخاب نمایند که چه تعداد بکاپ حفظ گردد. یک قسمت جدید دیگر در بکـاپ های File-Based ، Activities می باشد. هنگام که یک job بکآپ کامل می شود اطلاعات با جزییات این رویداد در قسمت Activity به عنوان گزارش قرار می گیرد. ما نمی توانیم بدون در نظر گرفتن Restore کردن در مورد بکآپ صحبت کنیم. روند کاری Restore ، اکنون شامل مرورگر آرشیو بکآپ ها می باشد. این مرورگر تمام بکاپ های شما بدون نیاز به دانستن مسیر های بکآپ نشان می دهد.
تب جدید دیگر Services می باشد که در VAMI قرار گرفته است. زمانی درون vSphere Web Client بود و اکنون در VAMIبرای عیب یابی out of band هست . تمام سرویس های vCenter Server Appliance ، نوع راه اندازی، سلامت و وضعیت آنها در اینجا قابل مشاهده است . ما همچنین گزینه ای برای شروع، متوقف کردن و راه اندازی مجدد این سرویس ها در صورت نیاز داریم. در حالی که تب های Syslog و Update در VAMI جدید نیستند ، اما در این زمینه ها پیشرفت نیز وجود دارد. Syslog اکنون تا سه syslog forwarding targets پشتیبانی میکند. پیش از این vSphere 6.5 فقط از یکی پشتیبانی میکرد . اکنون انعطاف پذیری بیشتری در پچ کردن و به روز رسانی وجود دارد. از برگه Update، اکنون گزینه ای برای انتخاب اینکه کدام پچ یا به روز رسانی اعمال شود وجود دارد. مشتریان همچنین اطلاعات بیشتری از جمله نوع ، سطح لزوم و همچنین در صورت نیاز به راه اندازی مجدد را مشاهده میکنند. با باز کردن پنجره نمایش پچ یا به روز رسانی ، اطلاعات بیشتر در مورد آنچه که شامل است نمایش داده خواهد شد و در نهایت ، اکنون می توانیم پچ یا به روز رسانی را از VAMI نصب واجرا کنیم. این قابلیت قبلا تنها از طریق CLI در دسترس بود.
(vSphere
client(HTML5
از ویژگی هایی که در vSphere 6.
7روی آن سرمایه گذاری قابل توجه ای شده است VSphere client میباشد. VMware با معرفی vSphere 6.5 نسخه vSphere Client (HTML5) را معرفی کرد که در vCenter server Application از قابلیت های جزئی برخوردار بود. تیم فنی vSphere به سختی بر روی آن کار می کنند تا از ویژگی های بیشتری پشتیبانی نماید و بر اساس باز خورد مشتریان عملکرد و ویژگی آن بهبود چشم گیری یافته است. برخی از ویژگی های جدیدی که در نسخه vSphere client به روز شده شامل موارد زیر است:
- vSphere Update Manager
- Content Library
- vSAN
- Storage Policies
- Host Profiles
- vDS Topology Diagram
- Licensing
بعضی از به روز رسانی هایی که در بالا ذکر شده دارای تمام ویژگی های عملکردی نیست . VMware به روز رسانی های vSphere Client را ادامه خواهد داد تا با ارائه (patch/update) این موارد بهبود یابد.
اکنون در منوی مدیریت ، گزینه های PSC بین دو زبانه تقسیم می شوند. Certificate management دارای برگه خاص خود است و تمام تنظیمات مدیریتی دیگر زیر برگه configuration هستند.
CLI Tools
CLI در vCenter Server Appliance 6.
7نیز دارای برخی از پیشرفت های جدیدی است . اولین پیشرفت Repoint با استفاده cmsso-util است. در حالی که این یک ویژگی جدید نیست ، این قابلیت در vSphere 6.5 موجود نبود و در Vsphere 6.7 دوباره اجرایی شده است . ما در مورد vCenter Server Appliance که به صورت مجزا با SSO Vsphere هست صحبت می کنیم.
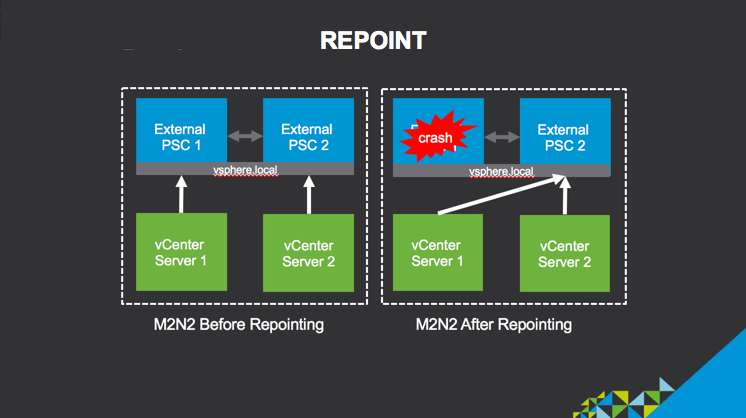
کاربران می توانند vCenter Server Appliance خود را از طریق vSphere SSO domains ، ریپوینت کنند. قابلیت Repoint فقط از external deployments که vSphere 6.
7دارد پشتیبانی میکند . قابلیت Repoint داخلی ویژگی pre-check دارد که من ترجیح میدهم استفاده نکنم ! ویژگی pre-check دو دامنه SSO را با هم مقایسه میکند و لیست اختلافات آنها را در یک فایل JSON ذخیره میکند. این فرصتی است که هر یک از این اختلافات را قبل از اجرای domain repoint tool حل کنید. ابزار repoint میتواند لایسنس ها ، تگ ها ، دسته بندی ها و permissions ها را از یک دامنه vSphere SSO به دیگری منتقل کند .
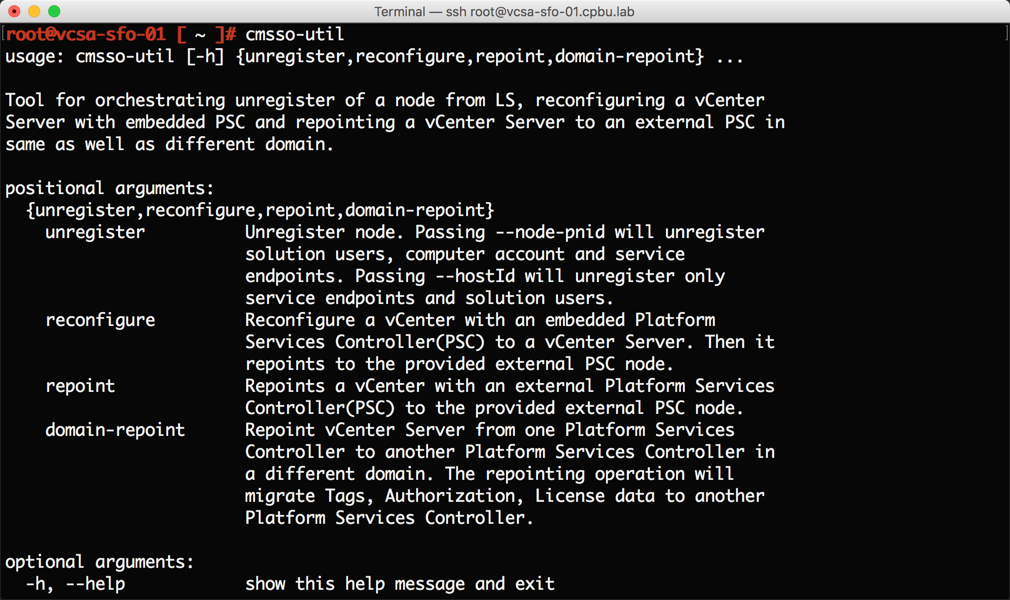
یکی دیگر از بهبود های CLI ، استفاده از cli installer ، برای مدیریت lifecycle در vCenter Server Appliance است .
vCenter Server Appliance ISO معمولا با JSON template examples همراه است. این JSON templates راهی برای اطمینان از سازگاری در طول نصب، ارتقاء و migrate است . معمولا ما باید یک JSON template را از cli installer در همان زمان و به روش صحیح اجرا کنیم . این پیاده سازی دستی per-node در حال حاضر با عملیات دسته ای ، از گذشته باقی مانده است. به عملیات دسته ای چندین JSON templates می تواند به طور متوالی از یک دایرکتوری بدون مداخله اجرا شود. برای تایید الگوها در دایرکتوری که شامل توالی است از گزینه pre-checks استفاده کنید.
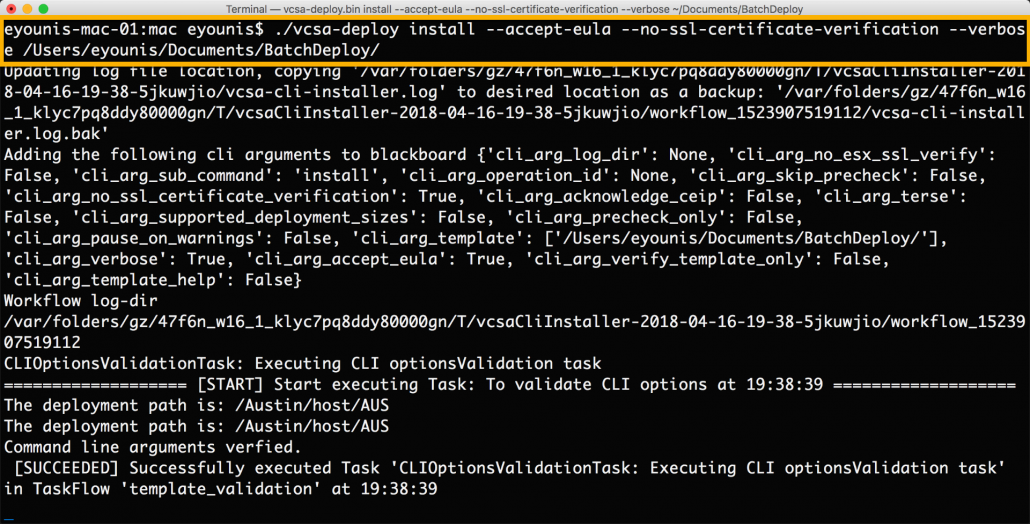
جمع بندی
خب ، vCenter Server Appliance 6.
7اکنون استاندارد جدیدی برای اجرای vCenter Server است . ما سعی خواهیم کرد چند مورد از ویژگی های برجسته این نخسه را بررسی کنیم .
مشاهده پست مشابه :
بروزرسانی به vSphere 6.7
:: برچسب ها :
آشنایی با vCenter Server 6,
7,
معرفی vCenter Server 6,
نسخه جدید vCenter,
ویژگی های vCenter Server 6,
ن : محمد
ت : سه شنبه 19 تير 1397
|
|
|





































